Publications
Publications by categories in reversed chronological order.
An up-to-date list is available on Google Scholar.
* denotes equal contribution
2026
- NeurIPS
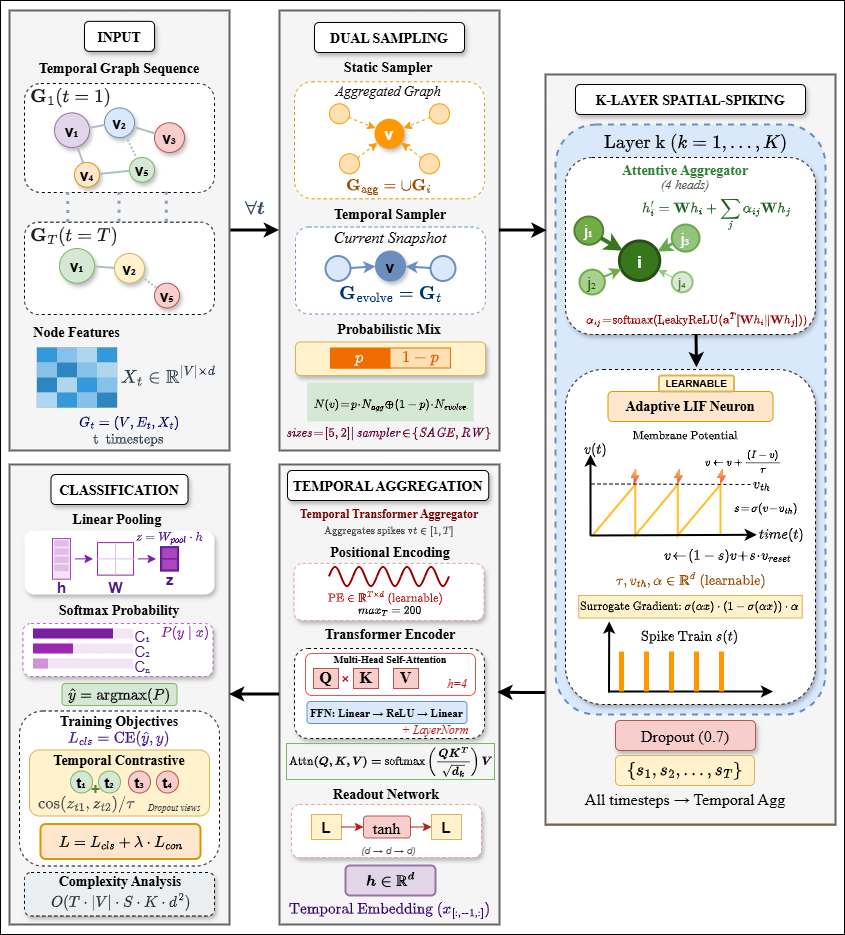 ChronoSpike: An Adaptive Spiking Graph Neural Network for Dynamic GraphsSubmitted to NeurIPS 2026, Jan 2026
ChronoSpike: An Adaptive Spiking Graph Neural Network for Dynamic GraphsSubmitted to NeurIPS 2026, Jan 2026Spiking neural networks (SNNs) offer a promising framework for dynamic graph learning through sparse, event-driven computation and inherent capacity to model temporal dynamics. However, existing spiking approaches struggle with limited adaptability and difficulty capturing long-range dependencies. We propose ChronoSpike, an adaptive spiking graph neural network that integrates multi-head neighborhood attention, learnable LIF neurons, and a lightweight Transformer-based temporal encoder. ChronoSpike models both fine-grained local interactions and global temporal dependencies while maintaining linear memory complexity and efficient temporal aggregation. Experiments on three large-scale dynamic graph benchmarks demonstrate that ChronoSpike consistently outperforms recent state-of-the-art methods, achieving average improvements of 2.0% Macro-F1 and 2.4% Micro-F1 while scaling efficiently to long temporal horizons. We provide a theoretical analysis guaranteeing training stability under temporal spiking dynamics, supported by comprehensive interpretability and parameter-sensitivity studies.
@article{jahin_chronospike_2026, journal = {Submitted to NeurIPS 2026}, title = {{ChronoSpike: An Adaptive Spiking Graph Neural Network for Dynamic Graphs}}, doi = {https://doi.org/10.48550/arXiv.2602.01124}, publisher = {arXiv}, author = {Jahin, Md Abrar and Fuad, Taufikur Rahman and Pujara, Jay and Knoblock, Craig}, month = jan, year = {2026}, note = {}, keywords = {Computer Science - Machine Learning}, } - Quantum Rationale-Aware Graph Contrastive Learning for Jet DiscriminationTransactions on Machine Learning Research (TMLR), Jan 2026arXiv:2411.01642
In high-energy physics, particle jet tagging plays a pivotal role in distinguishing quark from gluon jets using data from collider experiments. While graph-based deep learning methods have advanced this task beyond traditional feature-engineered approaches, the complex data structure and limited labeled samples present ongoing challenges. However, existing contrastive learning (CL) frameworks struggle to leverage rationale-aware augmentations effectively, often lacking supervision signals that guide the extraction of salient features and facing computational efficiency issues such as high parameter counts. In this study, we demonstrate that integrating a quantum rationale generator (QRG) within our proposed Quantum Rationale-aware Graph Contrastive Learning (QRGCL) framework significantly enhances jet discrimination performance, reducing reliance on labeled data and capturing discriminative features. Evaluated on the quark-gluon jet dataset, QRGCL achieves an AUC score of 77.5% while maintaining a compact architecture of only 45 QRG parameters, outperforming classical, quantum, and hybrid GCL and GNN benchmarks. These results highlight QRGCL’s potential to advance jet tagging and other complex classification tasks in high-energy physics, where computational efficiency and feature extraction limitations persist.
@article{jahin_quantum_2024, journal = {Transactions on Machine Learning Research (TMLR)}, title = {Quantum {Rationale}-{Aware} {Graph} {Contrastive} {Learning} for {Jet} {Discrimination}}, doi = {10.48550/arXiv.2411.01642}, publisher = {TMLR}, author = {Jahin, Md Abrar and Masud, Md Akmol and Mridha, M. F. and Dey, Nilanjan and Aung, Zeyar}, month = jan, year = {2026}, note = {arXiv:2411.01642}, keywords = {Computer Science - Machine Learning, High Energy Physics - Phenomenology}, } - Human-in-the-Loop Feature Selection Using Interpretable Kolmogorov-Arnold Network-based Double Deep Q-NetworkMd Abrar Jahin, M. F. Mridha, and Nilanjan DeyIEEE Open Journal of the Computer Society, Aug 2026arXiv:2411.03740
Feature selection is critical for improving the performance and interpretability of machine learning models, particularly in high-dimensional spaces where complex feature interactions can reduce accuracy and increase computational demands. Existing approaches often rely on static feature subsets or manual intervention, limiting adaptability and scalability. However, dynamic, per-instance feature selection methods and model-specific interpretability in reinforcement learning remain underexplored. This study proposes a human-in-the-loop (HITL) feature selection framework integrated into a Double Deep Q-Network (DDQN) using a Kolmogorov-Arnold Network (KAN). Our novel approach leverages simulated human feedback and stochastic distribution-based sampling, specifically Beta, to iteratively refine feature subsets per data instance, improving flexibility in feature selection. The KAN-DDQN achieved notable test accuracies of 93% on MNIST and 83% on FashionMNIST, outperforming conventional MLP-DDQN models by up to 9%. The KAN-based model provided high interpretability via symbolic representation while using 4 times fewer neurons in the hidden layer than MLPs did. Comparatively, the models without feature selection achieved test accuracies of only 58% on MNIST and 64% on FashionMNIST, highlighting significant gains with our framework. Pruning and visualization further enhanced model transparency by elucidating decision pathways. These findings present a scalable, interpretable solution for feature selection that is suitable for applications requiring real-time, adaptive decision-making with minimal human oversight.
@article{jahin_human---loop_2024, journal = {IEEE Open Journal of the Computer Society}, title = {Human-in-the-{Loop} {Feature} {Selection} {Using} {Interpretable} {Kolmogorov}-{Arnold} {Network}-based {Double} {Deep} {Q}-{Network}}, doi = {10.1109/OJCS.2026.3652986}, publisher = {IEEE}, volume = {7}, pages = {389-403}, author = {Jahin, Md Abrar and Mridha, M. F. and Dey, Nilanjan}, month = aug, year = {2026}, note = {arXiv:2411.03740}, keywords = {Computer Science - Machine Learning, Statistics - Applications, Computer Science - Human-Computer Interaction}, } - Stabilizing Federated Learning under Extreme Heterogeneity with HeteRo-SelectMd Akmol Masud, Md Abrar Jahin, and Mahmud HasanUnder review in IEEE Transactions on Artificial Intelligence, Jan 2026arXiv:2508.06692
Federated Learning (FL) is a machine learning technique that often suffers from training instability due to the diverse nature of client data. Although utility-based client selection methods like Oort are used to converge by prioritizing high-loss clients, they frequently experience significant drops in accuracy during later stages of training. We propose a theoretical HeteRo-Select framework designed to maintain high performance and ensure long-term training stability. We provide a theoretical analysis showing that when client data is very different (high heterogeneity), choosing a smart subset of client participation can reduce communication more effectively compared to full participation. Our HeteRo-Select method uses a clear, step-by-step scoring system that considers client usefulness, fairness, update speed, and data variety. It also shows convergence guarantees under strong regularization. Our experimental results on the CIFAR-10 dataset under significant label skew (α=0.1) support the theoretical findings. The HeteRo-Select method performs better than existing approaches in terms of peak accuracy, final accuracy, and training stability. Specifically, HeteRo-Select achieves a peak accuracy of 74.75%, a final accuracy of 72.76%, and a minimal stability drop of 1.99%. In contrast, Oort records a lower peak accuracy of 73.98%, a final accuracy of 71.25%, and a larger stability drop of 2.73%. The theoretical foundations and empirical performance in our study make HeteRo-Select a reliable solution for real-world heterogeneous FL problems.
@article{masud_hetero-select_2025, journal = {Under review in IEEE Transactions on Artificial Intelligence}, title = {{Stabilizing Federated Learning under Extreme Heterogeneity with HeteRo-Select}}, doi = {https://doi.org/10.48550/arXiv.2508.06692}, publisher = {arXiv}, author = {Masud, Md Akmol and Jahin, Md Abrar and Hasan, Mahmud}, month = jan, year = {2026}, note = {arXiv:2508.06692}, keywords = {Computer Science - Machine Learning}, } - Neurocomputing
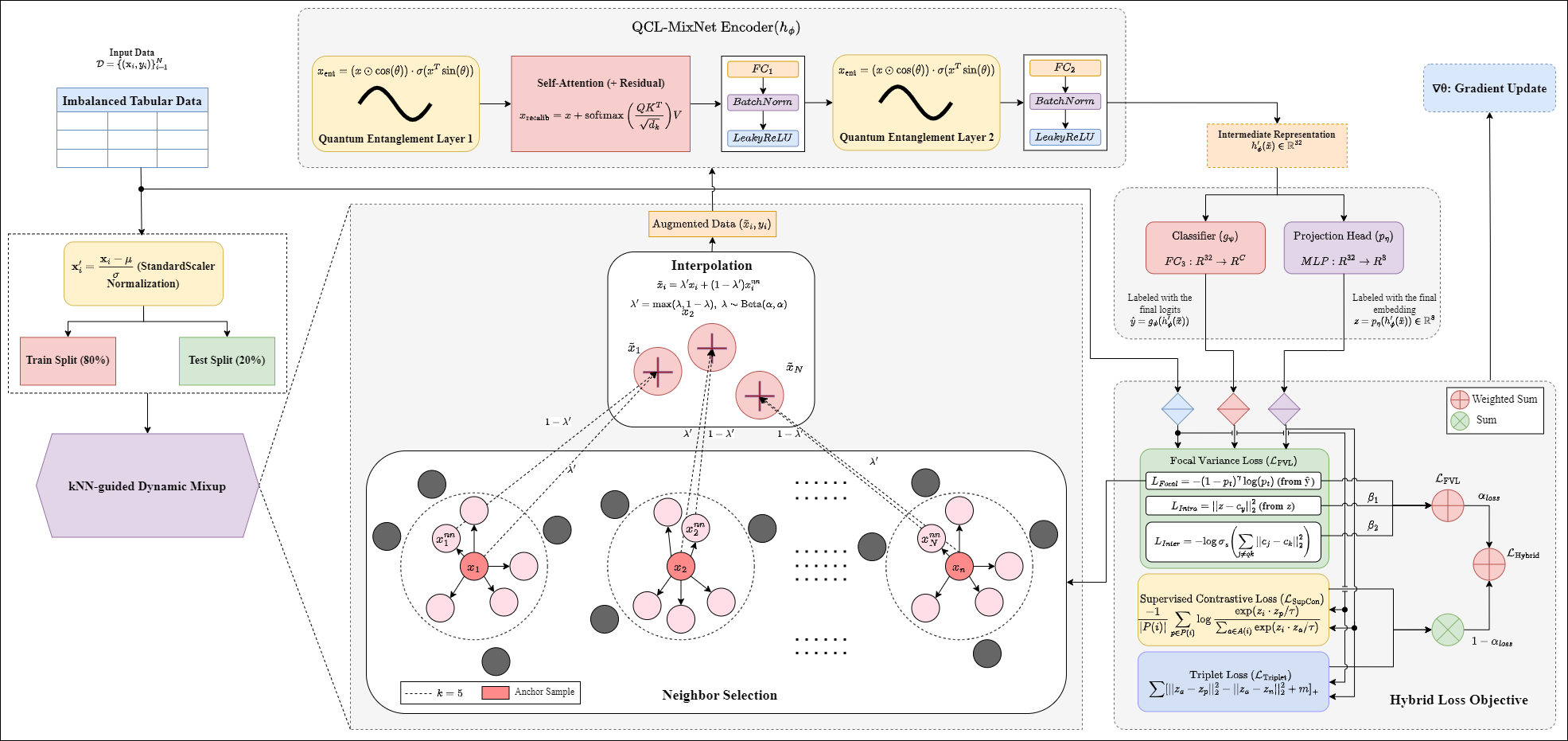 Quantum-Informed Contrastive Learning with Dynamic Mixup Augmentation for Class-Imbalanced Expert SystemsMd Abrar Jahin, Adiba Abid, and M. F. MridhaUnder review in Neurocomputing, Jun 2026arXiv:2503.01284
Quantum-Informed Contrastive Learning with Dynamic Mixup Augmentation for Class-Imbalanced Expert SystemsMd Abrar Jahin, Adiba Abid, and M. F. MridhaUnder review in Neurocomputing, Jun 2026arXiv:2503.01284Expert systems often operate in domains characterized by class-imbalanced tabular data, where detecting rare but critical instances is essential for safety and reliability. While conventional approaches, such as cost-sensitive learning, oversampling, and graph neural networks, provide partial solutions, they suffer from drawbacks like overfitting, label noise, and poor generalization in low-density regions. To address these challenges, we propose QCL-MixNet, a novel Quantum-Informed Contrastive Learning framework augmented with k-nearest neighbor (kNN) guided dynamic mixup for robust classification under imbalance. QCL-MixNet integrates three core innovations: (i) a Quantum Entanglement-inspired layer that models complex feature interactions through sinusoidal transformations and gated attention, (ii) a sample-aware mixup strategy that adaptively interpolates feature representations of semantically similar instances to enhance minority class representation, and (iii) a hybrid loss function that unifies focal reweighting, supervised contrastive learning, triplet margin loss, and variance regularization to improve both intra-class compactness and inter-class separability. Extensive experiments on 18 real-world imbalanced datasets (binary and multi-class) demonstrate that QCL-MixNet consistently outperforms 20 state-of-the-art machine learning, deep learning, and GNN-based baselines in macro-F1 and recall, often by substantial margins. Ablation studies further validate the critical role of each architectural component. Our results establish QCL-MixNet as a new benchmark for tabular imbalance handling in expert systems. Theoretical analyses reinforce its expressiveness, generalization, and optimization robustness.
@article{jahin_qcl-mixnet, journal = {Under review in Neurocomputing}, title = {{Quantum-Informed Contrastive Learning with Dynamic Mixup Augmentation for Class-Imbalanced Expert Systems}}, doi = {https://doi.org/10.48550/arXiv.2506.13987}, urldate = {2025-06-19}, publisher = {arXiv}, author = {Jahin, Md Abrar and Abid, Adiba and Mridha, M. F.}, month = jun, year = {2026}, note = {arXiv:2503.01284}, keywords = {Computer Science - Machine Learning}, } - SN Bus. Econ.
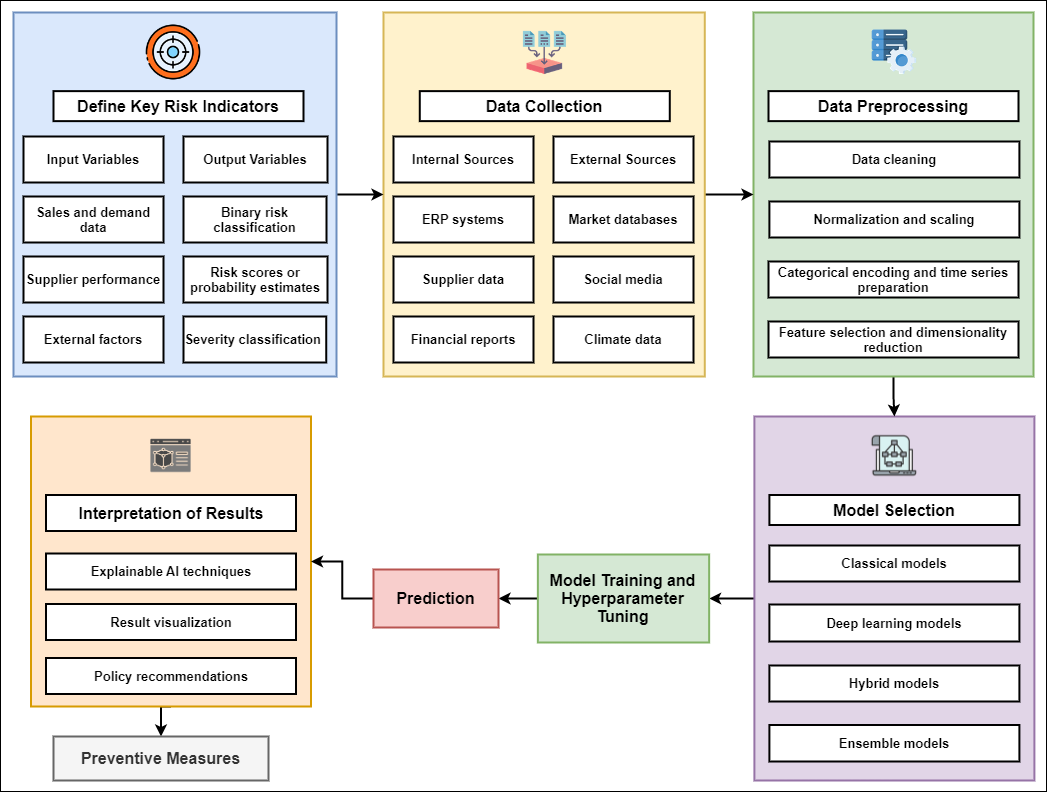 AI in Supply Chain Risk Assessment: A Systematic Literature Review and Bibliometric AnalysisUnder review in SN Business & Economics, Jan 2026arXiv:2401.10895 [cs]
AI in Supply Chain Risk Assessment: A Systematic Literature Review and Bibliometric AnalysisUnder review in SN Business & Economics, Jan 2026arXiv:2401.10895 [cs]Supply chain risk assessment (SCRA) has witnessed a profound evolution through the integration of artificial intelligence (AI) and machine learning (ML) techniques, revolutionizing predictive capabilities and risk mitigation strategies. The significance of this evolution stems from the critical role of robust risk management strategies in ensuring operational resilience and continuity within modern supply chains. Previous reviews have outlined established methodologies but have overlooked emerging AI/ML techniques, leaving a notable research gap in understanding their practical implications within SCRA. This paper conducts a systematic literature review combined with a comprehensive bibliometric analysis. We meticulously examined 1,717 papers and derived key insights from a select group of 48 articles published between 2014 and 2023. The review fills this research gap by addressing pivotal research questions, and exploring existing AI/ML techniques, methodologies, findings, and future trajectories, thereby providing a more encompassing view of the evolving landscape of SCRA. Our study unveils the transformative impact of AI/ML models, such as Random Forest, XGBoost, and hybrids, in substantially enhancing precision within SCRA. It underscores adaptable post-COVID strategies, advocating for resilient contingency plans and aligning with evolving risk landscapes. Significantly, this review surpasses previous examinations by accentuating emerging AI/ML techniques and their practical implications within SCRA. Furthermore, it highlights the contributions through a comprehensive bibliometric analysis, revealing publication trends, influential authors, and highly cited articles.
@article{jahin_ai_2024, journal = {Under review in SN Business & Economics}, title = {{AI} in {Supply} {Chain} {Risk} {Assessment}: {A} {Systematic} {Literature} {Review} and {Bibliometric} {Analysis}}, shorttitle = {{AI} in {Supply} {Chain} {Risk} {Assessment}}, doi = {10.48550/arXiv.2401.10895}, urldate = {2024-02-02}, publisher = {arXiv}, author = {Jahin, Md Abrar and Naife, Saleh Akram and Saha, Anik Kumar and Mridha, M. F.}, month = jan, year = {2026}, note = {arXiv:2401.10895 [cs]}, keywords = {Computer Science - Machine Learning, Computer Science - Computational Engineering, Finance, and Science}, }






2025
- CPC
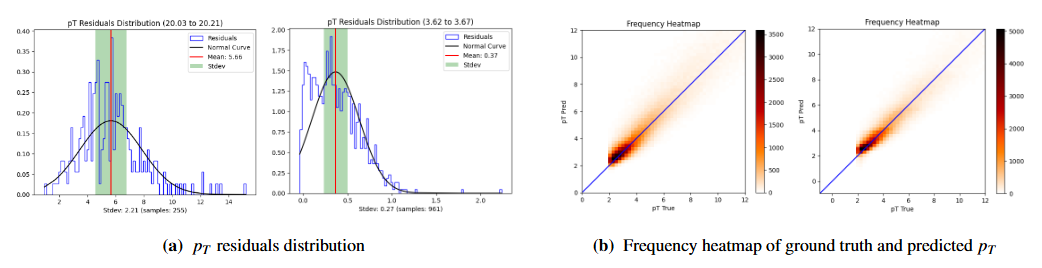 Physics-Informed Graph Neural Networks for Transverse Momentum Estimation in CMS Trigger SystemsUnder review in Computer Physics Communications, Jul 2025arXiv:2507.19205
Physics-Informed Graph Neural Networks for Transverse Momentum Estimation in CMS Trigger SystemsUnder review in Computer Physics Communications, Jul 2025arXiv:2507.19205Real-time particle transverse momentum (pT) estimation in high-energy physics demands algorithms that are both efficient and accurate under strict hardware constraints. Static machine learning models degrade under high pileup and lack physics-aware optimization, while generic graph neural networks (GNNs) often neglect domain structure critical for robust pT regression. We propose a physics-informed GNN framework that systematically encodes detector geometry and physical observables through four distinct graph construction strategies that systematically encode detector geometry and physical observables: station-as-node, feature-as-node, bending angle-centric, and pseudorapidity (η)-centric representations. This framework integrates these tailored graph structures with a novel Message Passing Layer (MPL), featuring intra-message attention and gated updates, and domain-specific loss functions incorporating pT-distribution priors. Our co-design methodology yields superior accuracy-efficiency trade-offs compared to existing baselines. Extensive experiments on the CMS Trigger Dataset validate the approach: a station-informed EdgeConv model achieves a state-of-the-art MAE of 0.8525 with ≥55% fewer parameters than deep learning baselines, especially TabNet, while an η-centric MPL configuration also demonstrates improved accuracy with comparable efficiency. These results establish the promise of physics-guided GNNs for deployment in resource-constrained trigger systems.
@article{jahin_cms-trigger-gnn, journal = {Under review in Computer Physics Communications}, title = {{Physics-Informed Graph Neural Networks for Transverse Momentum Estimation in CMS Trigger Systems}}, doi = {https://doi.org/10.48550/arXiv.2507.19205}, urldate = {2025-07-25}, publisher = {arXiv}, author = {Jahin, Md Abrar and Soudeep, Shahriar and Mridha, M. F. and Monowar, Muhammad Mostafa and Hamid, Md. Abdul}, month = jul, year = {2025}, note = {arXiv:2507.19205}, keywords = {Computer Science - Machine Learning}, } - IEEE DSAA
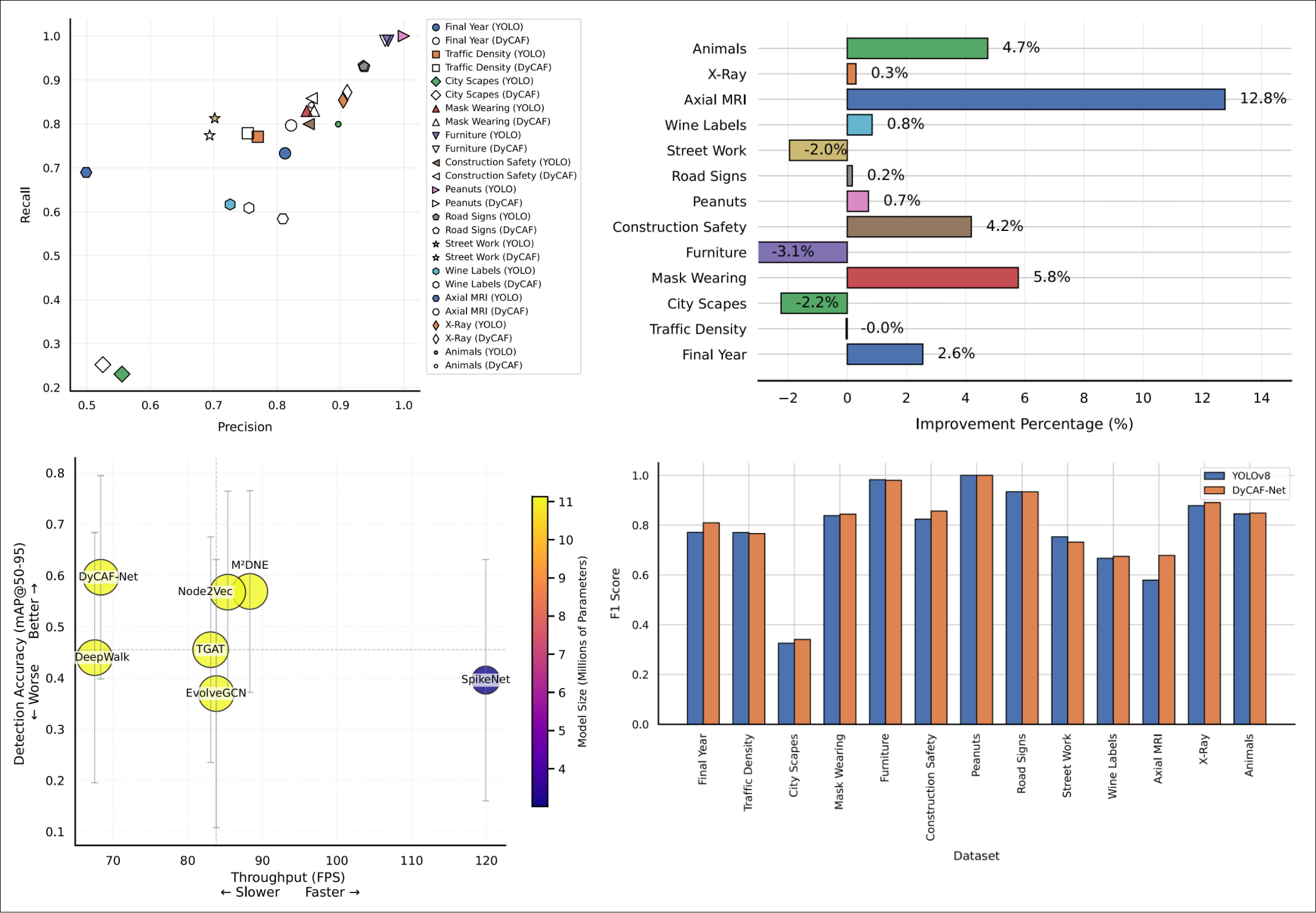 DyCAF-Net: Dynamic Class-Aware Fusion NetworkMd Abrar Jahin, Shahriar Soudeep, M. F. Mridha, Nafiz Fahad, and Md. Jakir Hossen2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA), Oct 2025Presented at the 12th IEEE International Conference on Data Science and Advanced Analytics (DSAA 2025) (CORE Rank: A), Birmingham, United Kingdom. October 9-12, 2025.
DyCAF-Net: Dynamic Class-Aware Fusion NetworkMd Abrar Jahin, Shahriar Soudeep, M. F. Mridha, Nafiz Fahad, and Md. Jakir Hossen2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA), Oct 2025Presented at the 12th IEEE International Conference on Data Science and Advanced Analytics (DSAA 2025) (CORE Rank: A), Birmingham, United Kingdom. October 9-12, 2025.Recent advancements in object detection rely on modular architectures with multi-scale fusion and attention mechanisms. However, static fusion heuristics and class-agnostic attention limit performance in dynamic scenes with occlusions, clutter, and class imbalance. We introduce Dynamic Class-Aware Fusion Network (DyCAF-Net), which addresses these challenges through three innovations: (1) an input-conditioned equilibrium-based neck that iteratively refines multi-scale features using implicit fixed-point modeling, (2) a dual dynamic attention mechanism that adaptively recalibrates channel and spatial responses based on input- and class-dependent cues, and (3) class-aware feature adaptation that adjusts features to prioritize discriminative regions for rare classes. Through comprehensive ablation studies with YOLOv8 and related architectures, and benchmarking against nine state-of-the-art baselines, DyCAF-Net achieves significant improvements in precision, mAP@50, and mAP@50–95 across 13 diverse benchmarks, including datasets with heavy occlusion and long-tailed distributions. The framework maintains computational efficiency ( 11.1M parameters) and competitive inference speeds, while its adaptability to scale variance, semantic overlaps, and class imbalance makes it a robust solution for real-world detection tasks in medical imaging, surveillance, and autonomous systems.
@article{jahin_dycaf-net_2025, journal = {2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA)}, title = {{DyCAF-Net: Dynamic Class-Aware Fusion Network}}, doi = {https://doi.org/10.1109/DSAA65442.2025.11247981}, publisher = {IEEE}, author = {Jahin, Md Abrar and Soudeep, Shahriar and Mridha, M. F. and Fahad, Nafiz and Hossen, Md. Jakir}, month = oct, year = {2025}, note = {Presented at the 12th IEEE International Conference on Data Science and Advanced Analytics (<span style="color:#7FFFD4; font-weight:bold;">DSAA 2025</span>) (<span style="color:red">CORE Rank: A</span>), Birmingham, United Kingdom. October 9-12, 2025.}, address = {Edgbaston Park Hotel, University of Birmingham, UK}, keywords = {Dynamic Object Detection, Class-Aware Attention, Multi-Scale Feature Fusion, Implicit Deep Equilibrium Models, Class Imbalance Mitigation, Occlusion-Robust Detection, Real-World Detection Benchmarks, Lightweight Detection Networks}, } - AdeptHEQ-FL: Adaptive Homomorphic Encryption for Federated Learning of Hybrid Classical-Quantum Models with Dynamic Layer Sparing2025 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Oct 2025Presented at the 1st International Workshop on Biomedical Image and Signal Computing for Unbiasedness, Interpretability, and Trustworthiness (BISCUIT) at ICCV 2025 (CORE Rank: A*), Honolulu, Hawaii, USA. October 19, 2025.
Federated Learning (FL) faces inherent challenges in balancing model performance, privacy preservation, and communication efficiency, especially in non-IID decentralized environments. Recent approaches either sacrifice formal privacy guarantees, incur high overheads, or overlook quantum-enhanced expressivity. We introduce AdeptHEQ-FL, a unified hybrid classical-quantum FL framework that integrates (i) a hybrid CNN-PQC architecture for expressive decentralized learning, (ii) an adaptive accuracy-weighted aggregation scheme leveraging differentially private validation accuracies, (iii) selective homomorphic encryption (HE) for secure aggregation of sensitive model layers, and (iv) dynamic layer-wise adaptive freezing to minimize communication overhead while preserving quantum adaptability. We establish formal privacy guarantees, provide convergence analysis, and conduct extensive experiments on the CIFAR-10, SVHN, and Fashion-MNIST datasets. AdeptHEQ-FL achieves a ≈25.43% and ≈14.17% accuracy improvement over Standard-FedQNN and FHE-FedQNN, respectively, on the CIFAR-10 dataset. Additionally, it reduces communication overhead by freezing less important layers, demonstrating the efficiency and practicality of our privacy-preserving, resource-aware design for FL. Our code is publicly available at: https://github.com/Abrar2652/QML-FL.
@article{jahin_adeptheq-fl_2025, journal = {2025 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, title = {{AdeptHEQ-FL: Adaptive Homomorphic Encryption for Federated Learning of Hybrid Classical-Quantum Models with Dynamic Layer Sparing}}, doi = {https://doi.org/10.48550/arXiv.2506.13987}, urldate = {2025-03-03}, publisher = {IEEE/CVF}, author = {Jahin, Md Abrar and Fuad, Taufikur Rahman and Mridha, M. F. and Fahad, Nafiz and Hossen, Md. Jakir}, month = oct, year = {2025}, pages = {552-561}, note = {Presented at the 1st International Workshop on Biomedical Image and Signal Computing for Unbiasedness, Interpretability, and Trustworthiness (BISCUIT) at <span style="color:#7FFFD4; font-weight:bold;">ICCV 2025</span> (<span style="color:red">CORE Rank: A*</span>), Honolulu, Hawaii, USA. October 19, 2025.}, address = {Honolulu, Hawaii, USA}, keywords = {Federated Learning, Quantum Neural Networks, Differential Privacy, Homomorphic Encryption, Communication-Efficient Learning, Hybrid Classical-Quantum Models, Privacy-Preserving Machine Learning, Strongly Entangling Layers, Adaptive Layer Freezing, Quantum Machine Learning}, } - Vision Transformers for End-to-End Quark-Gluon Jet Classification from Calorimeter ImagesMd Abrar Jahin, Shahriar Soudeep, Arian Rahman Aditta, M. F. Mridha, Nafiz Fahad, and 1 more authorIn Communications in Computer and Information Science, Aug 2025Presented at the Third International Workshop on Generalizing from Limited Resources in the Open World (GLOW) at IJCAI 2025 (CORE Rank: A*), Montreal, Canada. August 16, 2025.
Distinguishing between quark- and gluon-initiated jets is a critical and challenging task in high-energy physics, pivotal for improving new physics searches and precision measurements at the Large Hadron Collider. While deep learning, particularly Convolutional Neural Networks (CNNs), has advanced jet tagging using image-based representations, the potential of Vision Transformer (ViT) architectures, renowned for modeling global contextual information, remains largely underexplored for direct calorimeter image analysis, especially under realistic detector and pileup conditions. This paper presents a systematic evaluation of ViTs and ViT-CNN hybrid models for quark-gluon jet classification using simulated 2012 CMS Open Data. We construct multi-channel jet-view images from detector-level energy deposits (ECAL, HCAL) and reconstructed tracks, enabling an end-to-end learning approach. Our comprehensive benchmarking demonstrates that ViT-based models, notably ViT+MaxViT and ViT+ConvNeXt hybrids, consistently outperform established CNN baselines in F1-score, ROC-AUC, and accuracy, highlighting the advantage of capturing long-range spatial correlations within jet substructure. This work establishes the first systematic framework and robust performance baselines for applying ViT architectures to calorimeter image-based jet classification using public collider data, alongside a structured dataset suitable for further deep learning research in this domain.
@inproceedings{jahin_vitqg_ijcai_2025, booktitle = {Communications in Computer and Information Science}, title = {{Vision Transformers for End-to-End Quark-Gluon Jet Classification from Calorimeter Images}}, doi = {https://doi.org/10.1007/978-981-95-0988-1_10}, urldate = {2025-03-03}, publisher = {Springer Nature}, author = {Jahin, Md Abrar and Soudeep, Shahriar and Aditta, Arian Rahman and Mridha, M. F. and Fahad, Nafiz and Hossen, Md. Jakir}, month = aug, year = {2025}, volume = {2640}, note = {Presented at the Third International Workshop on Generalizing from Limited Resources in the Open World (GLOW) at <span style="color:#7FFFD4; font-weight:bold;">IJCAI 2025</span> (<span style="color:red">CORE Rank: A*</span>), Montreal, Canada. August 16, 2025.}, address = {Montreal, Canada}, keywords = {Vision Transformers, Deep Learning, End-to-End Learning, Quark-Gluon Classification, Jet Tagging, CMS Particle Reconstruction, Calorimeter Images, Particle Physics, High-Energy Physics}, } - Soybean Disease Detection via Interpretable Hybrid CNN-GNN: Integrating MobileNetV2 and GraphSAGE with Cross-Modal AttentionMd Abrar Jahin*, Shahriar Soudeep*, M. F. Mridha, and Nilanjan DeyUnder review in IEEE Access, Mar 2025arXiv:2503.01284
Soybean leaf disease detection is critical for agricultural productivity but faces challenges due to visually similar symptoms and limited interpretability in conventional methods. While Convolutional Neural Networks (CNNs) excel in spatial feature extraction, they often neglect inter-image relational dependencies, leading to misclassifications. This paper proposes an interpretable hybrid Sequential CNN-Graph Neural Network (GNN) framework that synergizes MobileNetV2 for localized feature extraction and GraphSAGE for relational modeling. The framework constructs a graph where nodes represent leaf images, with edges defined by cosine similarity-based adjacency matrices and adaptive neighborhood sampling. This design captures fine-grained lesion features and global symptom patterns, addressing inter-class similarity challenges. Cross-modal interpretability is achieved via Grad-CAM and Eigen-CAM visualizations, generating heatmaps to highlight disease-influential regions. Evaluated on a dataset of ten soybean leaf diseases, the model achieves 97.16% accuracy, surpassing standalone CNNs (≤95.04%) and traditional machine learning models (≤77.05%). Ablation studies validate the sequential architecture’s superiority over parallel or single-model configurations. With only 2.3 million parameters, the lightweight MobileNetV2-GraphSAGE combination ensures computational efficiency, enabling real-time deployment in resource-constrained environments. The proposed approach bridges the gap between accurate classification and practical applicability, offering a robust, interpretable tool for agricultural diagnostics while advancing CNN-GNN integration in plant pathology research.
@article{jahin_soybean_2025, journal = {Under review in IEEE Access}, title = {{Soybean Disease Detection via Interpretable Hybrid CNN-GNN: Integrating MobileNetV2 and GraphSAGE with Cross-Modal Attention}}, doi = {https://doi.org/10.48550/arXiv.2503.01284}, urldate = {2025-03-03}, publisher = {arXiv}, author = {Jahin*, Md Abrar and Soudeep*, Shahriar and Mridha, M. F. and Dey, Nilanjan}, month = mar, year = {2025}, note = {arXiv:2503.01284}, keywords = {Computer Science - Computer Vision and Pattern Recognition, Computer Science - Machine Learning}, } - CAGN-GAT Fusion: A Hybrid Contrastive Attentive Graph Neural Network for Network Intrusion DetectionMd Abrar Jahin*, Shahriar Soudeep*, M. F. Mridha, Raihan Kabir, Md Rashedul Islam, and 1 more authorIn Advances and Trends in Artificial Intelligence. Theory and Applications. Lecture Notes in Computer Science, Jul 2025Presented at the 38th International Conference on IEA/AIE 2025 (CORE Rank: C), Kitakyushu, Japan. July 1-4, 2025.
Cybersecurity threats are growing, making network intrusion detection essential. Traditional machine learning models remain effective in resource-limited environments due to their efficiency, requiring fewer parameters and less computational time. However, handling short and highly imbalanced datasets remains challenging. In this study, we propose the fusion of a Contrastive Attentive Graph Network and Graph Attention Network (CAGN-GAT Fusion) and benchmark it against 15 other models, including both Graph Neural Networks (GNNs) and traditional ML models. Our evaluation is conducted on four benchmark datasets (KDD-CUP-1999, NSL-KDD, UNSW-NB15, and CICIDS2017) using a short and proportionally imbalanced dataset with a constant size of 5000 samples to ensure fairness in comparison. Results show that CAGN-GAT Fusion demonstrates stable and competitive accuracy, recall, and F1-score, even though it does not achieve the highest performance in every dataset. Our analysis also highlights the impact of adaptive graph construction techniques, including small changes in connections (edge perturbation) and selective hiding of features (feature masking), improving detection performance. The findings confirm that GNNs, particularly CAGN-GAT Fusion, are robust and computationally efficient, making them well-suited for resource-constrained environments. Future work will explore GraphSAGE layers and multiview graph construction techniques to further enhance adaptability and detection accuracy.
@inproceedings{jahin_cagn-gat_2025, booktitle = {Advances and Trends in Artificial Intelligence. Theory and Applications. Lecture Notes in Computer Science}, title = {{CAGN-GAT Fusion: A Hybrid Contrastive Attentive Graph Neural Network for Network Intrusion Detection}}, doi = {https://doi.org/10.1007/978-981-96-8892-0_35}, urldate = {2025-03-02}, publisher = {Springer}, volume = {15707}, pages = {415–428}, author = {Jahin*, Md Abrar and Soudeep*, Shahriar and Mridha, M. F. and Kabir, Raihan and Islam, Md Rashedul and Watanobe, Yutaka}, month = jul, year = {2025}, note = {Presented at the 38th International Conference on <span style="color:#7FFFD4; font-weight:bold;">IEA/AIE 2025</span> (<span style="color:red">CORE Rank: C</span>), Kitakyushu, Japan. July 1-4, 2025.}, address = {Kitakyushu, Japan}, keywords = {Computer Science - Machine Learning}, } - Lorentz-Equivariant Quantum Graph Neural Network for High-Energy PhysicsIEEE Transactions on Artificial Intelligence, Mar 2025
The rapid data surge from the high-luminosity Large Hadron Collider introduces critical computational challenges requiring novel approaches for efficient data processing in particle physics. Quantum machine learning, with its capability to leverage the extensive Hilbert space of quantum hardware, offers a promising solution. However, current quantum graph neural networks (GNNs) lack robustness to noise and are often constrained by fixed symmetry groups, limiting adaptability in complex particle interaction modeling. This paper demonstrates that replacing the Lorentz Group Equivariant Block modules in LorentzNet with a dressed quantum circuit significantly enhances performance despite using nearly 5.5 times fewer parameters. Our Lorentz-Equivariant Quantum Graph Neural Network (Lorentz-EQGNN) achieved 74.00% test accuracy and an AUC of 87.38% on the Quark-Gluon jet tagging dataset, outperforming the classical and quantum GNNs with a reduced architecture using only 4 qubits. On the Electron-Photon dataset, Lorentz-EQGNN reached 67.00% test accuracy and an AUC of 68.20%, demonstrating competitive results with just 800 training samples. Evaluation of our model on generic MNIST and FashionMNIST datasets confirmed Lorentz-EQGNN’s efficiency, achieving 88.10% and 74.80% test accuracy, respectively. Ablation studies validated the impact of quantum components on performance, with notable improvements in background rejection rates over classical counterparts. These results highlight Lorentz-EQGNN’s potential for immediate applications in noise-resilient jet tagging, event classification, and broader data-scarce HEP tasks.
@article{jahin_lorentz-equivariant_2024, journal = {IEEE Transactions on Artificial Intelligence}, title = {Lorentz-{Equivariant} {Quantum} {Graph} {Neural} {Network} for {High}-{Energy} {Physics}}, doi = {10.1109/TAI.2025.3554461}, urldate = {2024-11-06}, publisher = {IEEE}, author = {Jahin, Md Abrar and Masud, Md Akmol and Suva, Md Wahiduzzaman and Mridha, M. F. and Dey, Nilanjan}, month = mar, year = {2025}, note = {}, keywords = {Computer Science - Machine Learning, High Energy Physics - Experiment, Physics - Instrumentation and Detectors}, } - KACQ-DCNN: Uncertainty-Aware Interpretable Kolmogorov-Arnold Classical-Quantum Dual-Channel Neural Network for Heart Disease DetectionComputers in Biology and Medicine, Aug 2025arXiv:2410.07446
Heart failure remains a major global health challenge, contributing significantly to the 17.8 million annual deaths from cardiovascular disease, highlighting the need for improved diagnostic tools. Current heart disease prediction models based on classical machine learning face limitations, including poor handling of high-dimensional, imbalanced data, limited performance on small datasets, and a lack of uncertainty quantification, while also being difficult for healthcare professionals to interpret. To address these issues, we introduce KACQ-DCNN, a novel classical-quantum hybrid dual-channel neural network that replaces traditional multilayer perceptrons and convolutional layers with Kolmogorov-Arnold Networks (KANs). This approach enhances function approximation with learnable univariate activation functions, reducing model complexity and improving generalization. The KACQ-DCNN 4-qubit 1-layered model significantly outperforms 37 benchmark models across multiple metrics, achieving an accuracy of 92.03%, a macro-average precision, recall, and F1 score of 92.00%, and an ROC-AUC score of 94.77%. Ablation studies demonstrate the synergistic benefits of combining classical and quantum components with KAN. Additionally, explainability techniques like LIME and SHAP provide feature-level insights, improving model transparency, while uncertainty quantification via conformal prediction ensures robust probability estimates. These results suggest that KACQ-DCNN offers a promising path toward more accurate, interpretable, and reliable heart disease predictions, paving the way for advancements in cardiovascular healthcare.
@article{jahin_kacq-dcnn_2024, journal = {Computers in Biology and Medicine}, title = {{KACQ}-{DCNN}: {Uncertainty}-{Aware} {Interpretable} {Kolmogorov}-{Arnold} {Classical}-{Quantum} {Dual}-{Channel} {Neural} {Network} for {Heart} {Disease} {Detection}}, shorttitle = {{KACQ}-{DCNN}}, doi = {10.1016/j.compbiomed.2025.110976}, urldate = {2025-08-17}, publisher = {arXiv}, author = {Jahin, Md Abrar and Masud, Md Akmol and Mridha, M. F. and Aung, Zeyar and Dey, Nilanjan}, month = aug, year = {2025}, note = {arXiv:2410.07446}, keywords = {Computer Science - Machine Learning}, } - Ultrasound-Based AI for COVID-19 Detection: A Comprehensive Review of Public and Private Lung Ultrasound Datasets and StudiesAbrar Morshed, Abdulla Al Shihab, Md Abrar Jahin*, Md Jaber Al Nahian, Md Murad Hossain Sarker, and 14 more authorsMultimedia Tools and Applications, Apr 2025
The COVID-19 pandemic has affected millions of people globally, with respiratory organs being strongly affected in individuals with comorbidities. Medical imaging-based diagnosis and prognosis have become increasingly popular in clinical settings for detecting COVID-19 lung infections. Among various medical imaging modalities, ultrasound stands out as a low-cost, mobile, and radiation-safe imaging technology. In this comprehensive review, we focus on AI-driven studies utilizing lung ultrasound (LUS) for COVID-19 detection and analysis. We provide a detailed overview of both publicly available and private LUS datasets and categorize the AI studies according to the dataset they used. Additionally, we systematically analyzed and tabulated the studies across various dimensions, including data preprocessing methods, AI models, cross-validation techniques, and evaluation metrics. In total, we reviewed 60 articles, 41 of which utilized public datasets, while the remaining employed private data. Our findings suggest that ultrasound-based AI studies for COVID-19 detection have great potential for clinical use, especially for children and pregnant women. Our review also provides a useful summary for future researchers and clinicians who may be interested in the field.
@article{morshed_ultrasound-based_2023, journal = {Multimedia Tools and Applications}, title = {Ultrasound-{Based} {AI} for {COVID}-19 {Detection}: {A} {Comprehensive} {Review} of {Public} and {Private} {Lung} {Ultrasound} {Datasets} and {Studies}}, shorttitle = {Ultrasound-{Based} {AI} for {COVID}-19 {Detection}}, doi = {10.1007/s11042-025-20802-5}, language = {en}, urldate = {2024-11-13}, publisher = {arXiv}, author = {Morshed, Abrar and Shihab, Abdulla Al and Jahin*, Md Abrar and Nahian, Md Jaber Al and Sarker, Md Murad Hossain and Wadud*, Md Sharjis Ibne and Uddin, Mohammad Istiaq and Siraji, Muntequa Imtiaz and Anjum, Nafisa and Shristy, Sumiya Rajjab and Rahman, Tanvin and Khatun, Mahmuda and Dewan, Md Rubel and Hossain, Mosaddeq and Sultana, Razia and Chakma, Ripel and Emon, Sonet Barua and Islam, Towhidul and Hussain*, Mohammad Arafat}, month = apr, year = {2025}, note = {}, keywords = {Computer Science - Artificial Intelligence, Computer Science - Computer Vision and Pattern Recognition}, } - TR-E
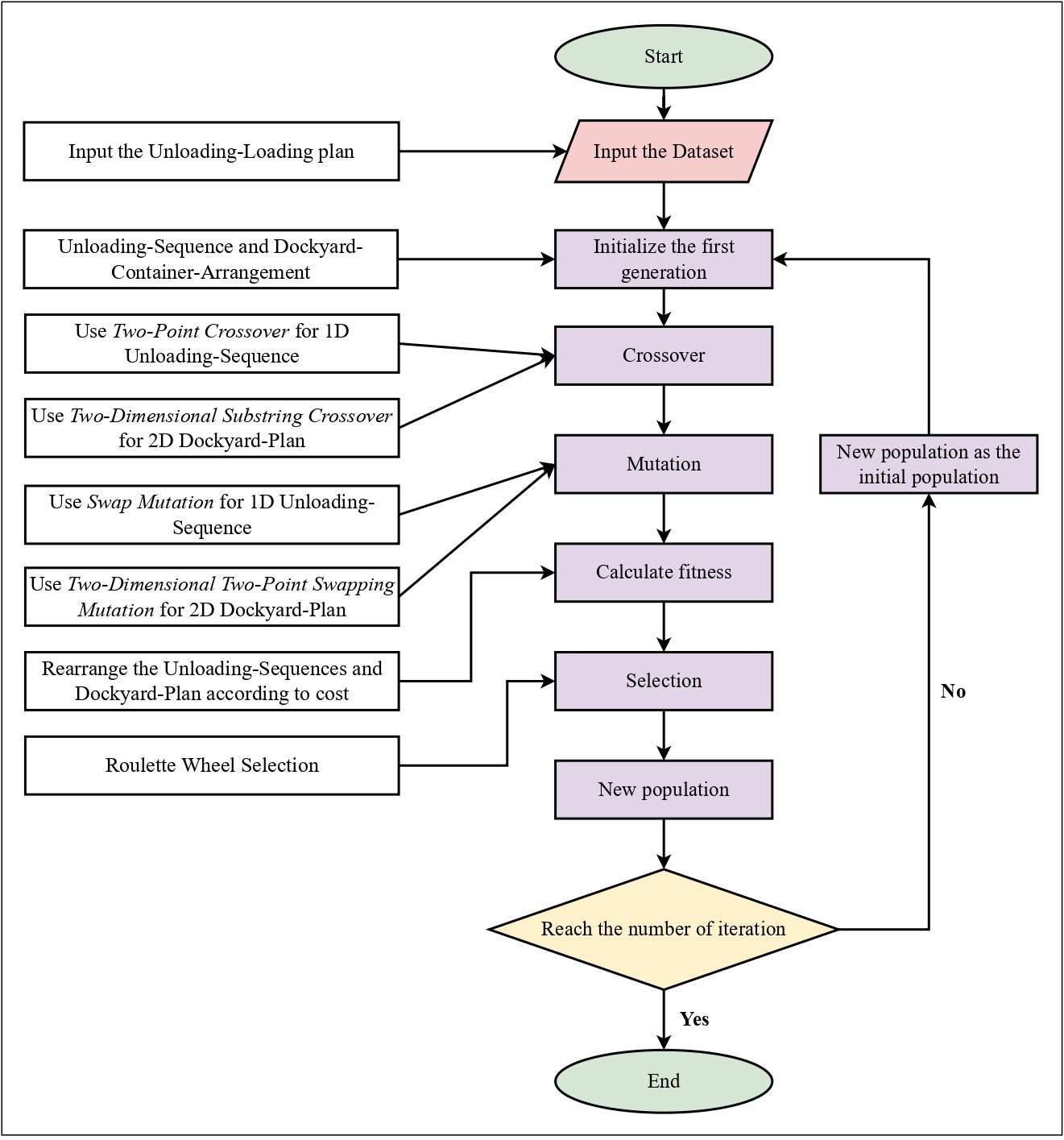 Optimizing Container Loading and Unloading through Dual-Cycling and Dockyard Rehandle Reduction Using a Hybrid Genetic AlgorithmMd Mahfuzur Rahman*, Md Abrar Jahin*, Md. Saiful Islam, M. F. Mridha, and Jungpil ShinUnder review in Journal of Ocean Engineering and Marine Energy, Oct 2025
Optimizing Container Loading and Unloading through Dual-Cycling and Dockyard Rehandle Reduction Using a Hybrid Genetic AlgorithmMd Mahfuzur Rahman*, Md Abrar Jahin*, Md. Saiful Islam, M. F. Mridha, and Jungpil ShinUnder review in Journal of Ocean Engineering and Marine Energy, Oct 2025@article{rahman_qcdc-dr-ga_2024, journal = {Under review in Journal of Ocean Engineering and Marine Energy}, title = {{Optimizing} {Container} {Loading} and {Unloading} through {Dual}-{Cycling} and {Dockyard} {Rehandle} {Reduction} {Using} a {Hybrid} {Genetic} {Algorithm}}, copyright = {https://creativecommons.org/licenses/by/4.0/}, shorttitle = {{QCDC}-{DR}-{GA}}, doi = {https://doi.org/10.48550/arXiv.2406.08534}, urldate = {2024-04-06}, author = {Rahman*, Md Mahfuzur and Jahin*, Md Abrar and Islam, Md. Saiful and Mridha, M. F. and Shin, Jungpil}, month = oct, year = {2025}, } - Predicting Male Domestic Violence Using Explainable Ensemble Learning and Exploratory Data AnalysisDiscover Applied Sciences, Dec 2025arXiv:2403.15594 [cs]
Domestic violence is commonly viewed as a gendered issue that primarily affects women, which tends to leave male victims largely overlooked. This study explores male domestic violence (MDV) for the first time, highlighting the factors that influence it and tackling the challenges posed by a significant categorical imbalance of 5:1 and a lack of data. We collected data from nine major cities in Bangladesh and conducted exploratory data analysis (EDA) to understand the underlying dynamics. EDA revealed patterns such as the high prevalence of verbal abuse, the influence of financial dependency, and the role of familial and socio-economic factors in MDV. To predict and analyze MDV, we implemented 10 traditional machine learning (ML) models, three deep learning models, and two ensemble models, including stacking and hybrid approaches. We propose a stacking ensemble model with ANN and CatBoost as base classifiers and Logistic Regression as the meta-model, which demonstrated the best performance, achieving 95% accuracy, a 99.29% AUC, and balanced metrics across evaluation criteria. Model-specific feature importance analysis of the base classifiers identified key features influencing their individual decision-making. Model-agnostic explainable AI techniques, SHAP and LIME, provided local and global insights into the decision-making processes of the proposed model, enhancing transparency and interpretability. Additionally, statistical validation using paired t-tests with 10-fold cross-validation and Bonferroni correction (alpha = 0.0036) confirmed the superior performance of our proposed model over alternatives.
@article{jahin_analyzing_2024, journal = {Discover Applied Sciences}, title = {{Predicting Male Domestic Violence Using Explainable Ensemble Learning and Exploratory Data Analysis}}, doi = {10.1007/s42452-025-07825-1}, urldate = {2024-04-06}, publisher = {arXiv}, author = {Jahin, Md Abrar and Naife, Saleh Akram and Lima, Fatema Tuj Johora and Mridha, M. F. and Hossen, Md. Jakir}, month = dec, year = {2025}, note = {arXiv:2403.15594 [cs]}, keywords = {Computer Science - Machine Learning, Computer Science - Computers and Society}, } - MCDFN: Supply Chain Demand Forecasting via an Explainable Multi-Channel Data Fusion Network ModelMd Abrar Jahin*, Asef Shahriar*, and Md Al AminEvolutionary Intelligence, May 2025arXiv:2405.15598 [cs] version: 1
Accurate demand forecasting is crucial for optimizing supply chain management. Traditional methods often fail to capture complex patterns from seasonal variability and special events. Despite advancements in deep learning, interpretable forecasting models remain a challenge. To address this, we introduce the Multi-Channel Data Fusion Network (MCDFN), a hybrid architecture that integrates Convolutional Neural Networks (CNN), Long Short-Term Memory networks (LSTM), and Gated Recurrent Units (GRU) to enhance predictive performance by extracting spatial and temporal features from time series data. Our rigorous benchmarking demonstrates that MCDFN outperforms seven other deep-learning models, achieving superior metrics: MSE (23.5738), RMSE (4.8553), MAE (3.9991), and MAPE (20.1575%). Additionally, MCDFN’s predictions were statistically indistinguishable from actual values, confirmed by a paired t-test with a 5% p-value and a 10-fold cross-validated statistical paired t-test. We apply explainable AI techniques like ShapTime and Permutation Feature Importance to enhance interpretability. This research advances demand forecasting methodologies and offers practical guidelines for integrating MCDFN into supply chain systems, highlighting future research directions for scalability and user-friendly deployment.
@article{jahin_mcdfn_2024, journal = {Evolutionary Intelligence}, title = {{MCDFN}: {Supply} {Chain} {Demand} {Forecasting} via an {Explainable} {Multi}-{Channel} {Data} {Fusion} {Network} {Model}}, shorttitle = {{MCDFN}}, doi = {https://doi.org/10.1007/s12065-025-01053-7}, urldate = {2024-05-27}, publisher = {arXiv}, author = {Jahin*, Md Abrar and Shahriar*, Asef and Amin, Md Al}, month = may, year = {2025}, volume = {18}, number = {66}, note = {arXiv:2405.15598 [cs] version: 1}, keywords = {Computer Science - Artificial Intelligence, Computer Science - Machine Learning}, }












2024
- DGNN-YOLO: Interpretable Dynamic Graph Neural Networks with YOLO11 for Small Occluded Object Detection and TrackingShahriar Soudeep*, Md Abrar Jahin*, and M. F. MridhaUnder review in Information Sciences, Nov 2024arXiv:2411.17251
The detection and tracking of small, occluded objects such as pedestrians, cyclists, and motorbikes pose significant challenges for traffic surveillance systems because of their erratic movement, frequent occlusion, and poor visibility in dynamic urban environments. Traditional methods like YOLO11, while proficient in spatial feature extraction for precise detection, often struggle with these small and dynamically moving objects, particularly in handling real-time data updates and resource efficiency. This paper introduces DGNN-YOLO, a novel framework that integrates dynamic graph neural networks (DGNNs) with YOLO11 to address these limitations. Unlike standard GNNs, DGNNs are chosen for their superior ability to dynamically update graph structures in real-time, which enables adaptive and robust tracking of objects in highly variable urban traffic scenarios. This framework constructs and regularly updates its graph representations, capturing objects as nodes and their interactions as edges, thus effectively responding to rapidly changing conditions. Additionally, DGNN-YOLO incorporates Grad-CAM, Grad-CAM++, and Eigen-CAM visualization techniques to enhance interpretability and foster trust, offering insights into the model’s decision-making process. Extensive experiments validate the framework’s performance, achieving a precision of 0.8382, recall of 0.6875, and mAP@0.5:0.95 of 0.6476, significantly outperforming existing methods. This study offers a scalable and interpretable solution for real-time traffic surveillance and significantly advances intelligent transportation systems’ capabilities by addressing the critical challenge of detecting and tracking small, occluded objects.
@article{soudeep_dgnn_2024, journal = {Under review in Information Sciences}, title = {{DGNN-YOLO: Interpretable Dynamic Graph Neural Networks with YOLO11 for Small Occluded Object Detection and Tracking}}, doi = {10.48550/arXiv.2411.17251}, urldate = {2024-12-02}, publisher = {arXiv}, author = {Soudeep*, Shahriar and Jahin*, Md Abrar and Mridha, M. F.}, month = nov, year = {2024}, note = {arXiv:2411.17251}, keywords = {Computer Science - Computer Vision and Pattern Recognition, Computer Science - Machine Learning}, } - IISE Trans.
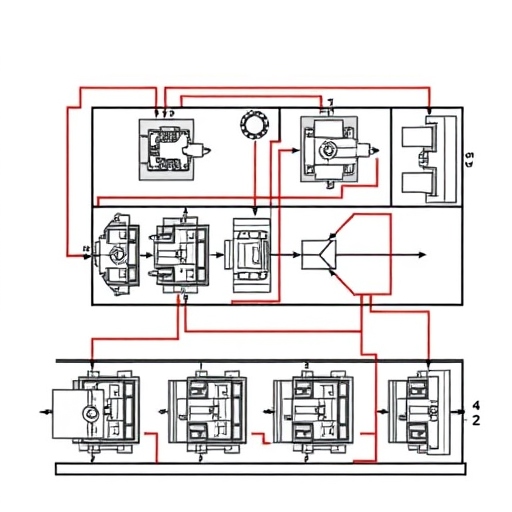 Designing Cellular Manufacturing System in Presence of Alternative Process PlansMd Kutub Uddin, Md. Saiful Islam, Md Abrar Jahin, Md Tanjid Hossen Irfan, Md. Saiful Islam Seam, and 1 more authorUnder review in IISE Transactions, Nov 2024arXiv:2411.15361
Designing Cellular Manufacturing System in Presence of Alternative Process PlansMd Kutub Uddin, Md. Saiful Islam, Md Abrar Jahin, Md Tanjid Hossen Irfan, Md. Saiful Islam Seam, and 1 more authorUnder review in IISE Transactions, Nov 2024arXiv:2411.15361In the design of cellular manufacturing systems (CMS), numerous technological and managerial decisions must be made at both the design and operational stages. The first step in designing a CMS involves grouping parts and machines. In this paper, four integer programming formulations are presented for grouping parts and machines in a CMS at both the design and operational levels for a generalized grouping problem, where each part has more than one process plan, and each operation of a process plan can be performed on more than one machine. The minimization of inter-cell and intra-cell movements is achieved by assigning the maximum possible number of consecutive operations of a part type to the same cell and to the same machine, respectively. The suitability of minimizing inter-cell and intra-cell movements as an objective, compared to other objectives such as minimizing investment costs on machines, operating costs, etc., is discussed. Numerical examples are included to illustrate the workings of the formulations.
@article{uddin_designing_2024, journal = {Under review in IISE Transactions}, title = {Designing {Cellular} {Manufacturing} {System} in {Presence} of {Alternative} {Process} {Plans}}, doi = {10.48550/arXiv.2411.15361}, urldate = {2024-11-22}, publisher = {arXiv}, author = {Uddin, Md Kutub and Islam, Md. Saiful and Jahin, Md Abrar and Irfan, Md Tanjid Hossen and Seam, Md. Saiful Islam and Mridha, M. F.}, month = nov, year = {2024}, note = {arXiv:2411.15361}, keywords = {Computer Science - Artificial Intelligence}, } - Solving Generalized Grouping Problems in Cellular Manufacturing Systems Using a Network Flow ModelMd Kutub Uddin, Md. Saiful Islam, Md Abrar Jahin, Md. Saiful Islam Seam, and M. F. MridhaUnder review in OPSEARCH, Nov 2024arXiv:2411.04685
This paper focuses on the generalized grouping problem in the context of cellular manufacturing systems (CMS), where parts may have more than one process route. A process route lists the machines corresponding to each part of the operation. Inspired by the extensive and widespread use of network flow algorithms, this research formulates the process route family formation for generalized grouping as a unit capacity minimum cost network flow model. The objective is to minimize dissimilarity (based on the machines required) among the process routes within a family. The proposed model optimally solves the process route family formation problem without pre-specifying the number of part families to be formed. The process route of family formation is the first stage in a hierarchical procedure. For the second stage (machine cell formation), two procedures, a quadratic assignment programming (QAP) formulation and a heuristic procedure, are proposed. The QAP simultaneously assigns process route families and machines to a pre-specified number of cells in such a way that total machine utilization is maximized. The heuristic procedure for machine cell formation is hierarchical in nature. Computational results for some test problems show that the QAP and the heuristic procedure yield the same results.
@article{uddin_solving_2024, journal = {Under review in OPSEARCH}, title = {Solving {Generalized} {Grouping} {Problems} in {Cellular} {Manufacturing} {Systems} {Using} a {Network} {Flow} {Model}}, doi = {10.48550/arXiv.2411.04685}, urldate = {2024-11-08}, publisher = {arXiv}, author = {Uddin, Md Kutub and Islam, Md. Saiful and Jahin, Md Abrar and Seam, Md. Saiful Islam and Mridha, M. F.}, month = nov, year = {2024}, note = {arXiv:2411.04685}, keywords = {Computer Science - Artificial Intelligence}, } - Quantum Mach. Intell.
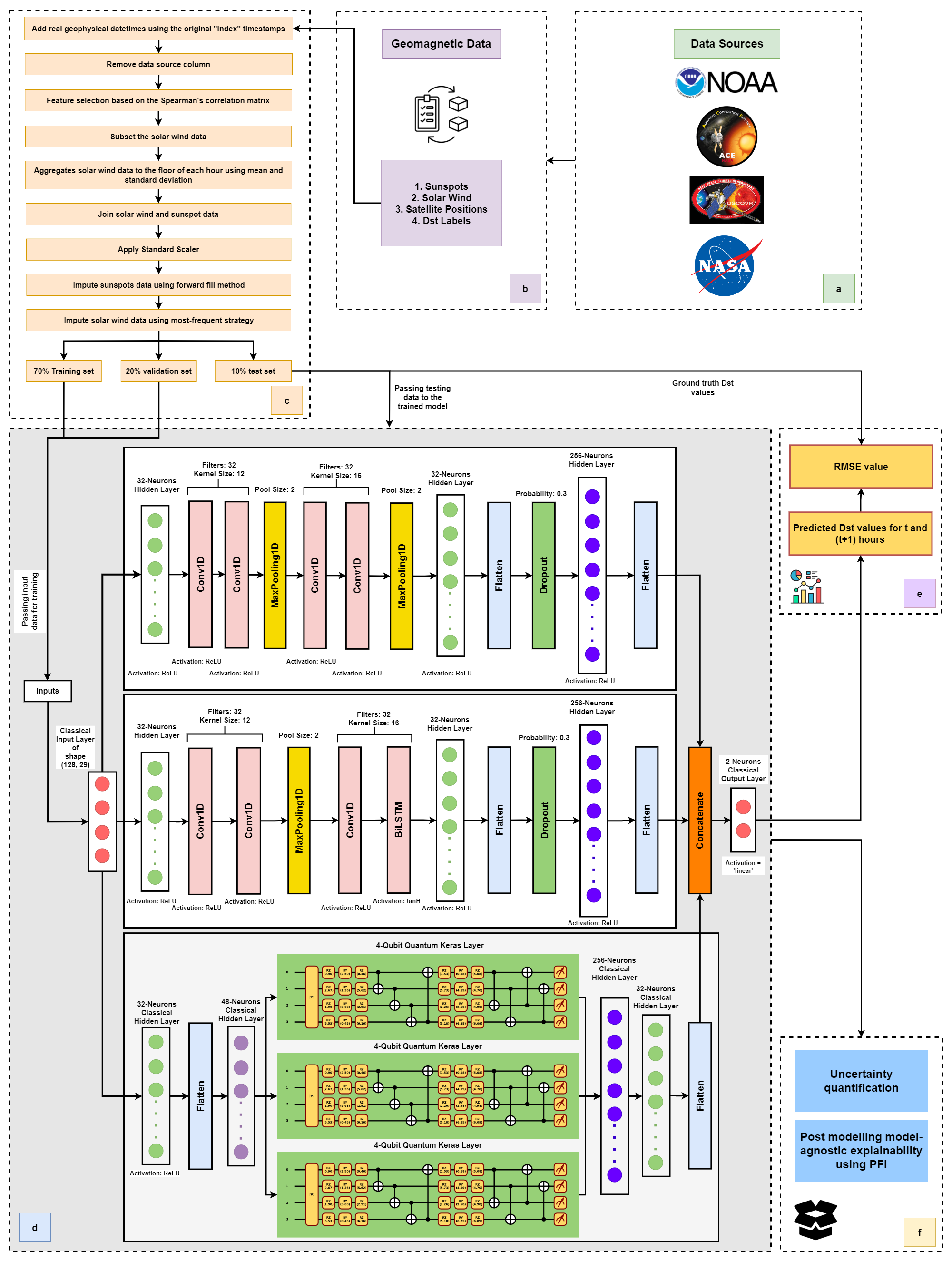 TriQXNet: Forecasting Dst Index from Solar Wind Data Using an Interpretable Parallel Classical-Quantum Framework with Uncertainty QuantificationUnder review in Quantum Machine Intelligence, Jul 2024arXiv:2407.06658 [cs]
TriQXNet: Forecasting Dst Index from Solar Wind Data Using an Interpretable Parallel Classical-Quantum Framework with Uncertainty QuantificationUnder review in Quantum Machine Intelligence, Jul 2024arXiv:2407.06658 [cs]Geomagnetic storms, which are brought on by the transmission of solar wind energy to the Earth’s magnetic field, have thepotential to substantially damage a number of critical infrastructure systems, including GPS, satellite communications, and electrical power grids. The disturbance storm-time (Dst) index is used to determine how strong these storms are. Using real-time solar wind data, a variety of models—empirical, physics-based, and machine-learning—have improved Dst forecasting during the last thirty years. However, forecasting extreme geomagnetic events is still difficult, requiring reliable ways to manage unprocessed, real-time data streams in the face of noise and sensor failures. This research aims to create a Dst forecasting model that employs specific real-time solar wind data feeds, functions under realistic restrictions, and outperforms state-of-the-art models in terms of prediction. Innovative methods are needed to solve this complex challenge, as it is not immediately evident what the optimal solution is. This study introduces a groundbreaking application of quantum computing inspace weather forecasting. Our novel framework represents a pioneering integration of classical and quantum computing,conformal prediction, and explainable AI (XAI) within a hybrid neural network architecture. To ensure high-quality input data,we developed a comprehensive data preprocessing pipeline that includes feature selection, normalization, aggregation, and imputation. The hybrid classical–quantum neural network, TriQXNet, leverages three parallel channels to process preprocessed solar wind data, significantly enhancing the robustness and accuracy of Dst index predictions. Our model predicts the Dst index using solar wind measurements from NASA’s ACE and NOAA’s DSCOVR satellites for the hour that is currently underway (t0)as well as the hour that will follow (t+1), providing vital advance notice to lessen the negative consequences of geomagnetic storms. TriQXNet outperforms 13 state-of-the-art hybrid deep-learning models, achieving a root mean squared error of 9.27 nanoteslas (nT). Rigorous evaluation through 10-fold cross-validated paired t-tests confirmed TriQXNet’s superior performance with 95% confidence. By implementing conformal prediction techniques, we provide quantifiable uncertainty in our forecasts, which is essential for operational decision-making. Additionally, incorporating XAI methods such as ShapTime and permutation feature importance enhances the interpretability of the model, fostering greater trust in its predictions. Comparative analysis revealed that TriQXNet outperforms existing models in the literature and the model deployed by the CIRES/NCEI geomagnetism team. Our model demonstrated exceptional forecasting accuracy for dual hours in a specific case study involving rapid Dstvalue decline. This research sets a new level of expectations for geomagnetic storm forecasting, showing the potential of classical–quantum hybrid models to improve space weather prediction capabilities.
@article{jahin_triqxnet_2024, journal = {Under review in Quantum Machine Intelligence}, title = {{TriQXNet}: {Forecasting} {Dst} {Index} from {Solar} {Wind} {Data} {Using} an {Interpretable} {Parallel} {Classical}-{Quantum} {Framework} with {Uncertainty} {Quantification}}, shorttitle = {{TriQXNet}}, doi = {10.48550/arXiv.2407.06658}, urldate = {2024-07-10}, publisher = {arXiv}, author = {Jahin, Md Abrar and Mridha, M. F. and Aung, Zeyar and Dey, Nilanjan and Sherratt, R. Simon}, month = jul, year = {2024}, note = {arXiv:2407.06658 [cs]}, keywords = {Computer Science - Artificial Intelligence}, } - Exploring Internet of Things adoption challenges in manufacturing firms: A Delphi Fuzzy Analytical Hierarchy Process approachHasan Shahriar*, Md. Saiful Islam, Md Abrar Jahin*, Istiyaque Ahmed Ridoy, Raihan Rafi Prottoy, and 2 more authorsPLoS ONE, Nov 2024Publisher: Public Library of Science
Innovation is crucial for sustainable success in today’s fiercely competitive global manufacturing landscape. Bangladesh’s manufacturing sector must embrace transformative technologies like the Internet of Things (IoT) to thrive in this environment. This article addresses the vital task of identifying and evaluating barriers to IoT adoption in Bangladesh’s manufacturing industry. Through synthesizing expert insights and carefully reviewing contemporary literature, we explore the intricate landscape of IoT adoption challenges. Our methodology combines the Delphi and Fuzzy Analytical Hierarchy Process, systematically analyzing and prioritizing these challenges. This approach harnesses expert knowledge and uses fuzzy logic to handle uncertainties. Our findings highlight key obstacles, with "Lack of top management commitment to new technology" (B10), "High initial implementation costs" (B9), and "Risks in adopting a new business model" (B7) standing out as significant challenges that demand immediate attention. These insights extend beyond academia, offering practical guidance to industry leaders. With the knowledge gained from this study, managers can develop tailored strategies, set informed priorities, and embark on a transformative journey toward leveraging IoT’s potential in Bangladesh’s industrial sector. This article provides a comprehensive understanding of IoT adoption challenges and equips industry leaders to navigate them effectively. This strategic navigation, in turn, enhances the competitiveness and sustainability of Bangladesh’s manufacturing sector in the IoT era.
@article{shahriar_exploring_2023, journal = {PLoS ONE}, title = {Exploring {Internet} of {Things} adoption challenges in manufacturing firms: {A} {Delphi} {Fuzzy} {Analytical} {Hierarchy} {Process} approach}, volume = {19}, issn = {1932-6203}, shorttitle = {Exploring {Internet} of {Things} adoption challenges in manufacturing firms}, doi = {10.1371/journal.pone.0311643}, language = {en}, number = {11}, urldate = {2024-11-04}, month = nov, year = {2024}, note = {Publisher: Public Library of Science}, keywords = {Cloud computing, Computer software, Decision making, Equipment, Finance, Industrial organization, Internet of Things, Wireless sensor networks}, pages = {e0311643}, author = {Shahriar*, Hasan and Islam, Md. Saiful and Jahin*, Md Abrar and Ridoy, Istiyaque Ahmed and Prottoy, Raihan Rafi and Abid, Adiba and Mridha, M. F.}, } - Anthropometric Data of KUET studentsMd Abrar Jahin, and Anik Kumar SahaFeb 2024Publisher: Mendeley Data
Number of male students: 300 Number of female students: 80 The anthropometric and NMQ data was collected from the students, including batches 2k18, 2k19, 2k20, and 2k21. Confidentiality of participant responses was strictly maintained. All data collected were anonymized and stored securely. Only the research team has access to the raw data, and findings will be reported in aggregate form to ensure the anonymity of participants. Participants were provided with informed consent forms detailing the purpose of the study, their rights as participants, and procedures for data handling. Participation in the survey was voluntary, and participants had the right to withdraw at any time without penalty. The NMQ study identified and ensured that musculoskeletal pain exists in university students. Cronbach alpha reliability test assured that the survey was within the acceptable range, thus being reliable.
@misc{jahin_anthropometric_2024, title = {Anthropometric {Data} of {KUET} students}, doi = {10.17632/kw7fd465v7.2}, language = {en}, urldate = {2024-03-03}, publisher = {Mendeley Data}, author = {Jahin, Md Abrar and Saha, Anik Kumar}, month = feb, year = {2024}, note = {Publisher: Mendeley Data}, } - Big Data—Supply Chain Management Framework for Forecasting: Data Preprocessing and Machine Learning TechniquesArchives of Computational Methods in Engineering, Mar 2024Publisher: Springer Nature
This article systematically identifies and comparatively analyzes state-of-the-art supply chain (SC) forecasting strategies and technologies within a specific timeframe, encompassing a comprehensive review of 152 papers spanning from 1969 to 2023. A novel framework has been proposed incorporating Big Data Analytics in SC Management (problem identification, data sources, exploratory data analysis, machine-learning model training, hyperparameter tuning, performance evaluation, and optimization), forecasting effects on human workforce, inventory, and overall SC. Initially, the need to collect data according to SC strategy and how to collect them has been discussed. The article discusses the need for different types of forecasting according to the period or SC objective. The SC KPIs and the error-measurement systems have been recommended to optimize the top-performing model. The adverse effects of phantom inventory on forecasting and the dependence of managerial decisions on the SC KPIs for determining model performance parameters and improving operations management, transparency, and planning efficiency have been illustrated. The cyclic connection within the framework introduces preprocessing optimization based on the post-process KPIs, optimizing the overall control process (inventory management, workforce determination, cost, production and capacity planning). The contribution of this research lies in the standard SC process framework proposal, recommended forecasting data analysis, forecasting effects on SC performance, machine learning algorithms optimization followed, and in shedding light on future research.
@article{jahin_big_2024, title = {Big {Data}—{Supply} {Chain} {Management} {Framework} for {Forecasting}: {Data} {Preprocessing} and {Machine} {Learning} {Techniques}}, issn = {1886-1784}, shorttitle = {Big {Data}—{Supply} {Chain} {Management} {Framework} for {Forecasting}}, doi = {10.1007/s11831-024-10092-9}, language = {en}, urldate = {2024-03-24}, journal = {Archives of Computational Methods in Engineering}, volume = {31}, pages = {3619-3645}, note = {Publisher: Springer Nature}, author = {Jahin, Md Abrar and Shovon, Md Sakib Hossain and Shin, Jungpil and Ridoy, Istiyaque Ahmed and Mridha, M. F.}, month = mar, year = {2024}, } - A hybrid transformer and attention based recurrent neural network for robust and interpretable sentiment analysis of tweetsScientific Reports, Oct 2024Publisher: Nature Publishing Group
Sentiment analysis is a pivotal tool in understanding public opinion, consumer behavior, and social trends, underpinning applications ranging from market research to political analysis. However, existing sentiment analysis models frequently encounter challenges related to linguistic diversity, model generalizability, explainability, and limited availability of labeled datasets. To address these shortcomings, we propose the Transformer and Attention-based Bidirectional LSTM for Sentiment Analysis (TRABSA) model, a novel hybrid sentiment analysis framework that integrates transformer-based architecture, attention mechanism, and recurrent neural networks like BiLSTM. The TRABSA model leverages the powerful RoBERTa-based transformer model for initial feature extraction, capturing complex linguistic nuances from a vast corpus of tweets. This is followed by an attention mechanism that highlights the most informative parts of the text, enhancing the model’s focus on critical sentiment-bearing elements. Finally, the BiLSTM networks process these refined features, capturing temporal dependencies and improving the overall sentiment classification into positive, neutral, and negative classes. Leveraging the latest RoBERTa-based transformer model trained on a vast corpus of 124M tweets, our research bridges existing gaps in sentiment analysis benchmarks, ensuring state-of-the-art accuracy and relevance. Furthermore, we contribute to data diversity by augmenting existing datasets with 411,885 tweets from 32 English-speaking countries and 7,500 tweets from various US states. This study also compares six word-embedding techniques, identifying the most robust preprocessing and embedding methodologies crucial for accurate sentiment analysis and model performance. We meticulously label tweets into positive, neutral, and negative classes using three distinct lexicon-based approaches and select the best one, ensuring optimal sentiment analysis outcomes and model efficacy. Here, we demonstrate that the TRABSA model outperforms the current seven traditional machine learning models, four stacking models, and four hybrid deep learning models, yielding notable gain in accuracy (94%) and effectiveness with a macro average precision of 94%, recall of 93%, and F1-score of 94%. Our further evaluation involves two extended and four external datasets, demonstrating the model’s consistent superiority, robustness, and generalizability across diverse contexts and datasets. Finally, by conducting a thorough study with SHAP and LIME explainable visualization approaches, we offer insights into the interpretability of the TRABSA model, improving comprehension and confidence in the model’s predictions. Our study results make it easier to analyze how citizens respond to resources and events during pandemics since they are integrated into a decision-support system. Applications of this system provide essential assistance for efficient pandemic management, such as resource planning, crowd control, policy formation, vaccination tactics, and quick reaction programs.
@article{jahin_trabsa_2024, title = {A hybrid transformer and attention based recurrent neural network for robust and interpretable sentiment analysis of tweets}, volume = {14}, copyright = {2024 The Author(s)}, issn = {2045-2322}, doi = {10.1038/s41598-024-76079-5}, language = {en}, number = {24882}, urldate = {2024-10-22}, journal = {Scientific Reports}, author = {Jahin, Md Abrar and Shovon, Md Sakib Hossain and Mridha, M. F. and Islam, Md Rashedul and Watanobe, Yutaka}, month = oct, year = {2024}, note = {Publisher: Nature Publishing Group}, keywords = {Computational science, Computer science}, pages = {24882}, } - SNCS
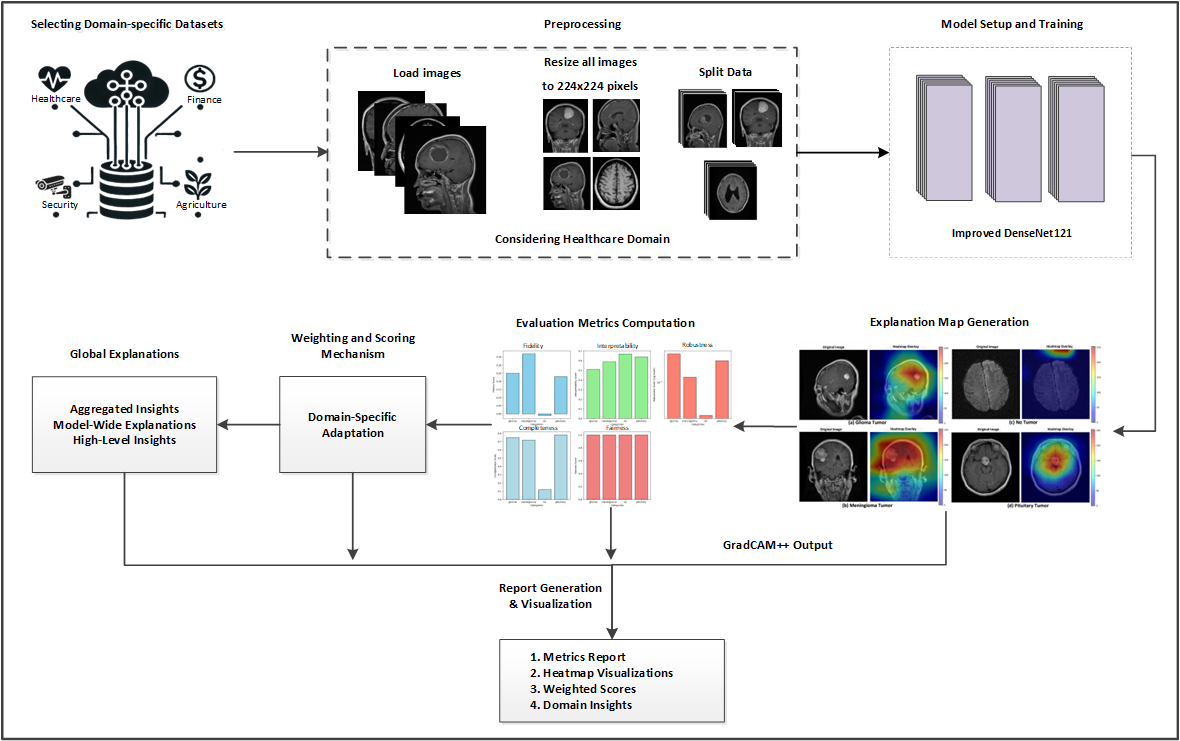 A Unified Framework for Evaluating the Effectiveness and Enhancing the Transparency of Explainable AI Methods in Real-World ApplicationsMd. Ariful Islam, Md Abrar Jahin, M. F. Mridha, and Nilanjan DeyUnder review in SN Computer Science, Mar 2024arXiv:2412.03884 [cs]
A Unified Framework for Evaluating the Effectiveness and Enhancing the Transparency of Explainable AI Methods in Real-World ApplicationsMd. Ariful Islam, Md Abrar Jahin, M. F. Mridha, and Nilanjan DeyUnder review in SN Computer Science, Mar 2024arXiv:2412.03884 [cs]The fast growth of deep learning has brought great progress in AI-based applications. However, these models are often seen as "black boxes," which makes them hard to understand, explain, or trust. Explainable Artificial Intelligence (XAI) tries to make AI decisions clearer so that people can understand how and why the model makes certain choices. Even though many studies have focused on XAI, there is still a lack of standard ways to measure how well these explanation methods work in real-world situations. This study introduces a single evaluation framework for XAI. It uses both numbers and user feedback to check if the explanations are correct, easy to understand, fair, complete, and reliable. The framework focuses on users’ needs and different application areas, which helps improve the trust and use of AI in important fields. To fix problems in current evaluation methods, we propose clear steps, including loading data, creating explanations, and fully testing them. We also suggest setting common benchmarks. We show the value of this framework through case studies in healthcare, finance, farming, and self-driving systems. These examples prove that our method can support fair and trustworthy evaluation of XAI methods. This work gives a clear and practical way to improve transparency and trust in AI systems used in the real world.
@article{islam_unifiedframework_2024, journal = {Under review in SN Computer Science}, title = {{A Unified Framework for Evaluating the Effectiveness and Enhancing the Transparency of Explainable AI Methods in Real-World Applications}}, doi = {10.48550/arXiv.2412.03884}, urldate = {2024-12-05}, publisher = {arXiv}, author = {Islam, Md. Ariful and Jahin, Md Abrar and Mridha, M. F. and Dey, Nilanjan}, month = mar, year = {2024}, note = {arXiv:2412.03884 [cs]}, keywords = {Computer Science - Machine Learning, Computer Science - Computers and Society}, } - Patient Comments and Specialist Types DatasetMd Abrar JahinApr 2024Publisher: Mendeley Data
This dataset contains patient comments, associated patient categories, and specialist types. Each entry in the dataset corresponds to a patient comment along with the category of the patient’s condition and the specialist type recommended for that category. The specialist types are mapped to the patient categories using a predefined dictionary. This dataset can be used for sentiment analysis, patient category classification, and specialist recommendation systems in healthcare. The dataset is provided in CSV format and can be used for research and analysis in the healthcare domain.
@misc{jahin_patient_2024, title = {Patient {Comments} and {Specialist} {Types} {Dataset}}, doi = {10.17632/2twgjzpn82.2}, language = {en}, urldate = {2024-04-22}, publisher = {Mendeley Data}, author = {Jahin, Md Abrar}, month = apr, year = {2024}, note = {Publisher: Mendeley Data}, } - A Natural Language Processing-Based Classification and Mode-Based Ranking of Musculoskeletal Disorder Risk FactorsMd Abrar Jahin, and Subrata TalapatraDecision Analytics Journal, Jun 2024Publisher: Elsevier
This research explores the intricate landscape of Musculoskeletal Disorder (MSD) risk factors, employing a novel fusion of Natural Language Processing (NLP) techniques and mode-based ranking methodologies. Enhancing knowledge of MSD risk factors, their classification, and their relative severity is the main goal of enabling more focused preventative and treatment efforts. The study benchmarks eight NLP models, integrating pre-trained transformers, cosine similarity, and various distance metrics to categorize risk factors into personal, biomechanical, workplace, psychological, and organizational classes. Key findings reveal that the Bidirectional Encoder Representations from Transformers (BERT) model with cosine similarity attains an overall accuracy of 28%, while the sentence transformer, coupled with Euclidean, Bray–Curtis, and Minkowski distances, achieves a flawless accuracy score of 100%. Using a 10-fold cross-validation strategy and performing rigorous statistical paired t-tests and Cohen’s d tests (with a 5% significance level assumed), the study provides the results with greater validity. To determine the severity hierarchy of MSD risk variables, the research uses survey data and a mode-based ranking technique parallel to the classification efforts. Intriguingly, the rankings align precisely with the previous literature, reaffirming the consistency and reliability of the approach. "Working posture" emerges as the most severe risk factor, emphasizing the critical role of proper posture in preventing MSD. The collective perceptions of survey participants underscore the significance of factors like "Job insecurity", "Effort reward imbalance", and "Poor employee facility" in contributing to MSD risks. The convergence of rankings provides actionable insights for organizations aiming to reduce the prevalence of MSD. The study concludes with implications for targeted interventions, recommendations for improving workplace conditions, and avenues for future research. This holistic approach, integrating NLP and mode-based ranking, contributes to a more sophisticated comprehension of MSD risk factors and opens the door for more effective strategies in occupational health.
@article{jahin_natural_2024, title = {A {Natural} {Language} {Processing}-{Based} {Classification} and {Mode}-{Based} {Ranking} of {Musculoskeletal} {Disorder} {Risk} {Factors}}, volume = {11}, issn = {2772-6622}, doi = {10.1016/j.dajour.2024.100464}, urldate = {2024-04-27}, journal = {Decision Analytics Journal}, publisher = {Elsevier}, number = {100464}, author = {Jahin, Md Abrar and Talapatra, Subrata}, month = jun, year = {2024}, keywords = {Machine learning, Risk factors, Occupational health and safety, Natural Language Processing (NLP), Musculoskeletal Disorder (MSD)}, pages = {100464}, note = {Publisher: Elsevier}, } - Bangladeshi Male Domestic Abuse DatasetMd Abrar JahinFeb 2024Publisher: Mendeley Data
The dataset comprises responses from diverse individuals, addressing demographic factors (residence type, age, education level, family structure), monthly income, initial experience of torture, current abuse situation, marital duration, extramarital involvement, primary abuse location, stance on male torture legislation, abuse victimization status, among others. Collected through a survey consisting of 22 questions, predominantly offering binary responses, it encompasses quantitative data derived from individual male responses. The survey targeted 2000 residents from Bangladesh’s 9 major cities, prioritizing professionals across sectors and ensuring representation of unemployed individuals, employees, and business owners.
@misc{jahin_bangladeshi_2024, title = {Bangladeshi {Male} {Domestic} {Abuse} {Dataset}}, doi = {10.17632/97xnx8nf22.2}, language = {en}, urldate = {2024-04-27}, publisher = {Mendeley Data}, author = {Jahin, Md Abrar}, month = feb, year = {2024}, note = {Publisher: Mendeley Data}, } - Analysis of Internet of things Implementation Barriers in the Cold Supply Chain: An Integrated ISM-MICMAC and DEMATEL ApproachKazrin Ahmad*, Md. Saiful Islam, Md Abrar Jahin*, and M. F. MridhaPLoS ONE, Jul 2024Publisher: Public Library of Science (PLoS), arXiv:2402.01804 [cs]
Integrating Internet of Things (IoT) technology inside the cold supply chain can enhance transparency, efficiency, and quality, optimize operating procedures, and increase productivity. The integration of the IoT in this complicated setting is hindered by specific barriers that require thorough examination. Prominent barriers to IoT implementation in a cold supply chain, which is the main objective, are identified using a two-stage model. After reviewing the available literature on IoT implementation, 13 barriers were identified. The survey data were cross-validated for quality, and Cronbach’s alpha test was employed to ensure validity. This study applies the interpretative structural modeling technique in the first phase to identify the main barriers. Among these barriers, "regulatory compliance" and "cold chain networks" are the key drivers of IoT adoption strategies. MICMAC’s driving and dependence power element categorization helps evaluate barrier interactions. In the second phase of this study, a decision-making trial and evaluation laboratory methodology was employed to identify causal relationships between barriers and evaluate them according to their relative importance. Each cause is a potential drive, and if its efficiency can be enhanced, the system benefits as a whole. The findings provide industry stakeholders, governments, and organizations with significant drivers of IoT adoption to overcome these barriers and optimize the utilization of IoT technology to improve the effectiveness and reliability of the cold supply chain.
@article{ahmad_analysis_2024, journal = {PLoS ONE}, title = {Analysis of {Internet} of {things} {Implementation} {Barriers} in the {Cold} {Supply} {Chain}: {An} {Integrated} {ISM}-{MICMAC} and {DEMATEL} {Approach}}, shorttitle = {Analysis of {Internet} of {things} {Implementation} {Barriers} in the {Cold} {Supply} {Chain}}, doi = {10.1371/journal.pone.0304118}, urldate = {2024-07-12}, publisher = {PLoS ONE}, author = {Ahmad*, Kazrin and Islam, Md. Saiful and Jahin*, Md Abrar and Mridha, M. F.}, month = jul, year = {2024}, volume = {19}, number = {7}, note = {Publisher: Public Library of Science (PLoS), arXiv:2402.01804 [cs]}, keywords = {Computer Science - Artificial Intelligence, Computer Science - Computers and Society}, } - Ergonomic Design of Computer Laboratory Furniture: Mismatch Analysis Utilizing Anthropometric Data of University StudentsHeliyon, Jul 2024Publisher: Elsevier, arXiv:2403.05589 [cs]
Many studies have shown that ergonomically designed furniture improves productivity and well-being. As computers have become a part of students’ academic lives, they will continue to grow in the future. We propose anthropometric-based furniture dimensions that are suitable for university students to improve computer laboratory ergonomics. We collected data from 380 participants and analyzed 11 anthropometric measurements, correlating them with 11 furniture dimensions. Two types of furniture were found and studied in different university computer laboratories: (1) a non-adjustable chair with a non-adjustable table and (2) an adjustable chair with a non-adjustable table. The mismatch calculation showed a significant difference between existing furniture dimensions and anthropometric measurements, indicating that 7 of the 11 existing furniture dimensions need improvement. The one-way ANOVA test with a significance level of 5% also showed a significant difference between the anthropometric data and existing furniture dimensions. All 11 dimensions were determined to match students’ anthropometric data. The proposed dimensions were found to be more compatible and showed reduced mismatch percentages for nine furniture dimensions and nearly zero mismatches for seat width, backrest height, and under the hood for both males and females compared to the existing furniture dimensions. The proposed dimensions of the furniture set with adjustable seat height showed slightly improved match results for seat height and seat-to-table clearance, which showed zero mismatches compared with the non-adjustable furniture set. The table width and table depth dimensions were suggested according to Barnes and Squires’ ergonomic work envelope model, considering hand reach. The positions of the keyboard and mouse are also suggested according to the work envelope. The monitor position and viewing angle were proposed according to OSHA guidelines. This study suggests that the proposed dimensions can improve comfort levels, reducing the risk of musculoskeletal disorders among students. Further studies on the implementation and long-term effects of the proposed dimensions in real-world computer laboratory settings are recommended.
@article{saha_ergonomic_2024, journal = {Heliyon}, title = {Ergonomic {Design} of {Computer} {Laboratory} {Furniture}: {Mismatch} {Analysis} {Utilizing} {Anthropometric} {Data} of {University} {Students}}, shorttitle = {Ergonomic {Design} of {Computer} {Laboratory} {Furniture}}, doi = {10.1016/j.heliyon.2024.e34063}, urldate = {2024-07-09}, publisher = {Elsevier}, author = {Saha*, Anik Kumar and Jahin*, Md Abrar and Rafiquzzaman, Md and Mridha, M. F.}, month = jul, year = {2024}, volume = {10}, number = {14}, note = {Publisher: Elsevier, arXiv:2403.05589 [cs]}, keywords = {Computer Science - Artificial Intelligence, Computer Science - Human-Computer Interaction}, }














2023
- Extended Covid Twitter DatasetsMd Abrar JahinMay 2023Publisher: Mendeley Data
Wider spatiotemporal English COVID-19 Tweets
@misc{jahin_extended_2023, title = {Extended {Covid} {Twitter} {Datasets}}, doi = {10.17632/2ynwykrfgf.1}, language = {en}, urldate = {2023-07-26}, publisher = {Mendeley Data}, author = {Jahin, Md Abrar}, month = may, year = {2023}, note = {Publisher: Mendeley Data}, } - QAmplifyNet: pushing the boundaries of supply chain backorder prediction using interpretable hybrid quantum-classical neural networkMd Abrar Jahin, Md Sakib Hossain Shovon, Md. Saiful Islam, Jungpil Shin, M. F. Mridha, and 1 more authorScientific Reports, Oct 2023Number: 1 Publisher: Nature Publishing Group
Supply chain management relies on accurate backorder prediction for optimizing inventory control, reducing costs, and enhancing customer satisfaction. Traditional machine-learning models struggle with large-scale datasets and complex relationships. This research introduces a novel methodological framework for supply chain backorder prediction, addressing the challenge of collecting large real-world datasets with 90% accuracy. Our proposed model demonstrates remarkable accuracy in predicting backorders on short and imbalanced datasets. We capture intricate patterns and dependencies by leveraging quantum-inspired techniques within the quantum-classical neural network QAmplifyNet. Experimental evaluations on a benchmark dataset establish QAmplifyNet’s superiority over eight classical models, three classically stacked quantum ensembles, five quantum neural networks, and a deep reinforcement learning model. Its ability to handle short, imbalanced datasets makes it ideal for supply chain management. We evaluate seven preprocessing techniques, selecting the best one based on logistic regression’s performance on each preprocessed dataset. The model’s interpretability is enhanced using Explainable artificial intelligence techniques. Practical implications include improved inventory control, reduced backorders, and enhanced operational efficiency. QAmplifyNet also achieved the highest F1-score of 94% for predicting "Not Backorder" and 75% for predicting "backorder," outperforming all other models. It also exhibited the highest AUC-ROC score of 79.85%, further validating its superior predictive capabilities. QAmplifyNet seamlessly integrates into real-world supply chain management systems, empowering proactive decision-making and efficient resource allocation. Future work involves exploring additional quantum-inspired techniques, expanding the dataset, and investigating other supply chain applications. This research unlocks the potential of quantum computing in supply chain optimization and paves the way for further exploration of quantum-inspired machine learning models in supply chain management. Our framework and QAmplifyNet model offer a breakthrough approach to supply chain backorder prediction, offering superior performance and opening new avenues for leveraging quantum-inspired techniques in supply chain management.
@article{jahin_qamplifynet_2023, title = {{QAmplifyNet}: pushing the boundaries of supply chain backorder prediction using interpretable hybrid quantum-classical neural network}, copyright = {2023 Springer Nature Limited}, issn = {2045-2322}, shorttitle = {{QAmplifyNet}}, doi = {10.1038/s41598-023-45406-7}, language = {en}, urldate = {2023-10-25}, journal = {Scientific Reports}, volume = {13}, number = {1}, author = {Jahin, Md Abrar and Shovon, Md Sakib Hossain and Islam, Md. Saiful and Shin, Jungpil and Mridha, M. F. and Okuyama, Yuichi}, month = oct, year = {2023}, note = {Number: 1 Publisher: Nature Publishing Group}, keywords = {Mathematics and computing, Engineering}, pages = {18246}, } - Perfectly Conserved Sequences (PCS) Between Human and Mouse Are Significantly Enriched for Small-protein Coding SequenceLucia Žifčáková, and Md Abrar JahinIn Society for Molecular Biology and Evolution (SMBE), Jul 2023
We extracted PCS from the UCSC human and mouse genome alignment after the removal of repetitive sequences. We leveraged RefSeq, SmProt, and Enhanceratlas databases for PCS annotation by all known human genes, small proteins, and enhancers, respectively. We have created 1000 sets of "random PCS," each with the same length distribution as natural PCS but randomly located in the nonrepetitive part of the genome. To test for enrichment of small proteins in PCS, we applied Fisher’s exact test, and the hypergeometric test, phyper, in R. gProfiler (for coding regions) and GREAT (for non-coding, cisregulatory regions) was used to find enriched Gene Ontology (GO) terms in PCS annotated as small proteins. Both enrichment analyses use correction of the p-value for multiple hypothesis testing.
@inproceedings{zifcakova_perfectly_2023, address = {Ferrara, Emilia-Romagna, Italy}, title = {Perfectly {Conserved} {Sequences} ({PCS}) {Between} {Human} and {Mouse} {Are} {Significantly} {Enriched} for {Small}-protein {Coding} {Sequence}}, doi = {10.13140/RG.2.2.18559.11682}, language = {en}, urldate = {2024-02-03}, booktitle = {Society for {Molecular} {Biology} and {Evolution} ({SMBE})}, author = {Žifčáková, Lucia and Jahin, Md Abrar}, month = jul, year = {2023}, keywords = {comparative genomics, human-mouse genomes, pcs, perfectly conserved sequences, ucsc}, } - Survey Data on Ranking of Musculoskeletal Disorder Risk Factors - Mendeley DataMd Abrar JahinMay 2023Publisher: Mendeley Data
@misc{jahin_survey_2023, title = {Survey {Data} on {Ranking} of {Musculoskeletal} {Disorder} {Risk} {Factors} - {Mendeley} {Data}}, doi = {10.17632/kr33mvtw63.1}, language = {en}, urldate = {2024-03-29}, publisher = {Mendeley Data}, author = {Jahin, Md Abrar}, month = may, year = {2023}, note = {Publisher: Mendeley Data}, }




2022
- Perfectly conserved sequences (PCS) between human and mouse are significantly enriched for small proteinsLucia Žifčáková, Md Abrar Jahin, and Jonathan MillerIn Bioinformatics and Computational Biology Conference (BBCC), Dec 2022
This poster presents a study on the length distribution of Perfectly Conserved Sequences (PCS) and their enrichment in small proteins. The researchers analyzed whole-genome alignments of human and mouse genomes and classified PCS as exonic, intronic, or intergenomic. To assess the significance of PCS constraints, three sets of random PCS were created as negative controls. The findings revealed that natural PCS are 11 times more enriched in small proteins compared to random PCS. This research sheds light on the strong constraint on PCS sequences and provides valuable insights into genome evolution and conservation.
@inproceedings{zifcakova_perfectly_2022, title = {Perfectly conserved sequences ({PCS}) between human and mouse are significantly enriched for small proteins}, volume = {11}, doi = {10.13140/RG.2.2.16369.90723}, urldate = {2023-07-26}, booktitle = {Bioinformatics and {Computational} {Biology} {Conference} ({BBCC})}, author = {Žifčáková, Lucia and Jahin, Md Abrar and Miller, Jonathan}, month = dec, year = {2022}, }

2021
- DIT4BEARs Smart Roads InternshipMd Abrar Jahin, and Andrii KrutsyloJul 2021Internship Report at UiT-The Arctic University of Norway; Affiliated with DIT4BEARs project
The research internship at UiT - The Arctic University of Norway was offered for our team being the winner of the ’Smart Roads - Winter Road Maintenance 2021’ Hackathon. The internship commenced on 3 May 2021 and ended on 21 May 2021 with meetings happening twice each week. In spite of having different nationalities and educational backgrounds, we both interns tried to collaborate as a team as much as possible. The most alluring part was working on this project made us realize the critical conditions faced by the arctic people, where it was hard to gain such a unique experience from our residence. We developed and implemented several deep learning models to classify the states (dry, moist, wet, icy, snowy, slushy). Depending upon the best model, the weather forecast app will predict the state taking the Ta, Tsurf, Height, Speed, Water, etc. into consideration. The crucial part was to define a safety metric which is the product of the accident rates based on friction and the accident rates based on states. We developed a regressor that will predict the safety metric depending upon the state obtained from the classifier and the friction obtained from the sensor data. A pathfinding algorithm has been designed using the sensor data, open street map data, weather data.
@misc{jahin_dit4bears_2021, title = {{DIT4BEARs} {Smart} {Roads} {Internship}}, doi = {10.48550/arXiv.2107.06755}, urldate = {2023-07-26}, publisher = {arXiv}, author = {Jahin, Md Abrar and Krutsylo, Andrii}, month = jul, year = {2021}, note = {Internship Report at UiT-The Arctic University of Norway; Affiliated with DIT4BEARs project}, keywords = {Computer Science - Machine Learning}, annote = {Comment: 6 pages}, }
